高性能计算平台是一款腾讯云自研的高性能计算资源管理服务,集成腾讯云上的计算、存储、网络等产品资源,并整合HPC专用作业管理调度、集群管理等软件,向用户提供弹性灵活、性能卓越、自助化的计算服务。本文以使用VASP软件进行高性能计算介绍如何配置自动伸缩策略。
背景信息
当您需要每天不定时提交作业,使用THPC集群几个小时进行大规模计算,然后释放节点,您可以针对不同的作业类型,配置不同的伸缩策略。配置伸缩策略后,系统可以根据实时负载自动增加或减少计算节点。可以帮您合理利用资源,减少使用成本。
前置条件
请依照准备工作中的指引获取SecretId和SecretKey,并完成服务角色授权。
操作步骤
1、安装最新版本的TCCLI命令工具,并进行初始化配置请参见THPC地域列表。
2、使用CreateCluster接口创建一个有1个管控节点0个计算节点的THPC集群。
执行命令:
tccli thpc CreateCluster --cli-input-json file://./test.jsontest.json文件参数配置可参考:
{
"Placement": {
"Zone": "ap-chongqing-1"
},
"ManagerNodeCount": 1,
"ManagerNode": {
"InternetAccessible": {
"InternetMaxBandwidthOut": 10
},
"InstanceName": "ThpcTestSlurmManagerNode",
"InstanceType": "S5.MEDIUM4"
},
"SchedulerType": "SLURM",
"LoginSettings": {
"Password": "xxxxxxxx"
},
"ImageId": "img-l8og963d",
"VirtualPrivateCloud": {
"VpcId": "vpc-r9jw2jzv",
"SubnetId": "subnet-0v4eybey"
},
"AutoScalingType": "THPC_AS"
}
提交请求并执行完毕后,您需要记录ClusterId:

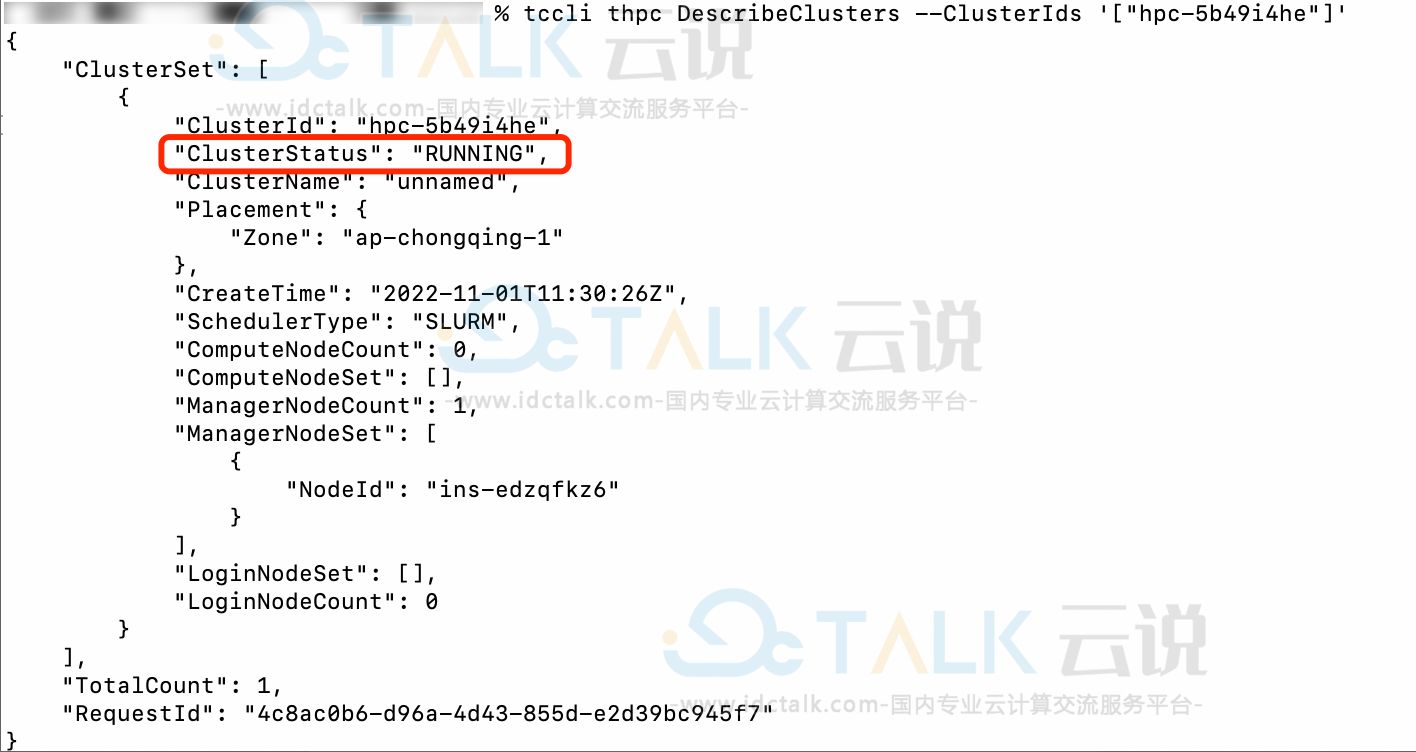
使用ClusterId查询集群状态:
tccli thpc DescribeClusters --ClusterIds '["hpc-xxxxxxxx"]'返回结果,其中:
ClusterStatus为RUNNING状态表示集群创建完成,可以开始使用。
ClusterStatus为INITING状态表示集群正在初始化中,需要等待直到为RUNNING或者INIT_FAILED状态之一。
ClusterStatus为INIT_FAILED状态表示集群创建失败,您可以使用API Explorer查看集群活动查看详细集群状态信息。
3、使用SetAutoScalingConfiguration接口开启THPC AS功能。
tccli thpc SetAutoScalingConfiguration --cli-input-json file://./SetAutoScalingConfiguration.json{
"ClusterId": "hpc-xxxxxxxx",
"ExpansionBusyTime": 120,
"ShrinkIdleTime": 120,
"QueueConfigs": [{
"QueueName": "compute",
"MinSize": 1,
"MaxSize": 5,
"EnableAutoExpansion": true,
"EnableAutoShrink": true,
"ExpansionNodeConfigs": [{
"Placement": {
"Zone": "ap-chongqing-1"
},
"VirtualPrivateCloud": {
"VpcId": "vpc-r9jw2jzv",
"SubnetId": "subnet-0v4eybey"
},
"InstanceType": "S6.4XLARGE32"
}, {
"Placement": {
"Zone": "ap-chongqing-1"
},
"VirtualPrivateCloud": {
"VpcId": "vpc-r9jw2jzv",
"SubnetId": "subnet-0v4eybey"
},
"InstanceType": "S6.2XLARGE32"
}]
}]
}
以上SetAutoScalingConfiguration.json文件接口配置好集群自动扩缩容参数如下:
- 开启Slurm调度器compute队列的自动扩容能力,THPC会根据扩容策略对连续等待超过120秒的作业进行自动扩容,并且弹性节点的最大值不超过5个。ExpansionBusyTime参数取值最小值为120s。
- 开启Slurm调度器compute队列的自动缩容能力,THPC会对连续空闲超过120s的节点进行自动缩容,并且弹性节点的最小值不小于1个。ShrinkIdleTime取值最小值为0s。compute队列配置了两个扩容机型。
|
序号
|
机型
|
CPU
|
|
1
|
S6.4XLARGE32
|
16
|
|
2
|
S6.2XLARGE32
|
8
|
4、登录管控节点提交VASP作业:submit.sh脚本内容如下,脚本提交一个vasp作业,在一个节点上使用8个核运行:
#!/bin/sh
#SBATCH -p compute
#SBATCH -o job.%j.out
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=8
#SBATCH -D /opt/graphene
source /opt/intel/oneapi/setvars.sh
/opt/intel/oneapi/mpi/2021.7.0/bin/mpirun -n 16 /opt/vasp.6.3.0/bin/vasp_std
提交作业前,集群没有任何节点存在:

提交作业:
sbatch submit.sh5、集群扩容并执行作业,作业结束后缩容到0节点。提交作业之后,THPC会根据扩容策略,扩容出最匹配的两个8核的S6.2XLARGE32实例。等待约4~8分钟后,节点加入集群并运行提交的作业。

任务执行完成之后,节点进入空闲(idle)状态:

等待2~3分钟之后,会进行自动缩容到最小节点数:

6、使用完毕后,使用如下命令删除集群,关联的计算实例将会被销毁。
tccli thpc DeleteCluster --ClusterId hpc-xxxxxxxx