8月21日,快手AI团队宣布推出,从0到1独立自主研发的系列大语言模型“快意”(KwaiYii)。据悉,“快意”包含KwaiYii-13B-Base预训练模型和KwaiYii-13B-Chat对话模型。
其中,Base预训练模型在MMLU、CMMLU、C-Eval等权威的中/英文测试平台中,在同等模型中处于领先水平。Chat对话模型具备内容创作、信息咨询、数学推理、生成代码等能力,人工评估结果表明KwaiYii-13B-Chat超过主流的开源模型,并在内容创作、信息咨询和数学解题上接近ChatGPT(3.5)同等水平。
开发团队选择了业内权威的Benchmark平台对Base、Chat模型进行测试,包括测试英文能力的MMLU、中文能力的C-Eval和CMMLU、中小学数学能力的GSM8K以及代码能力的HumanEval,并与主流模型的性能进行了横向对比。
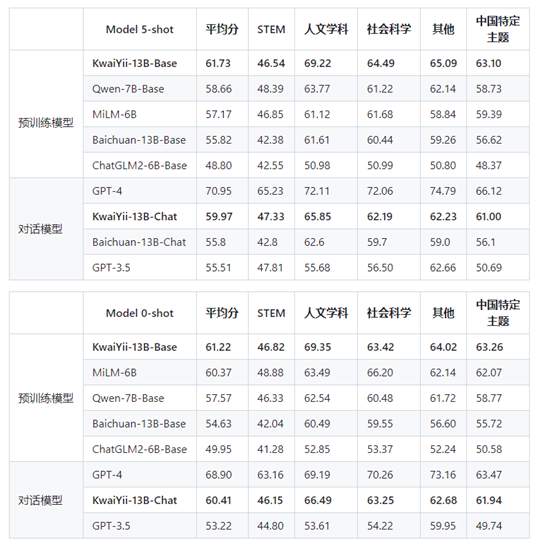
C-Eval:是一个全面的中文基础模型评测数据集,包含12342道单项选择题,涵盖数学、物理、化学、生物、历史、政治、计算机等52个不同学科和四个难度级别。采用5-shot的方式进行评测。
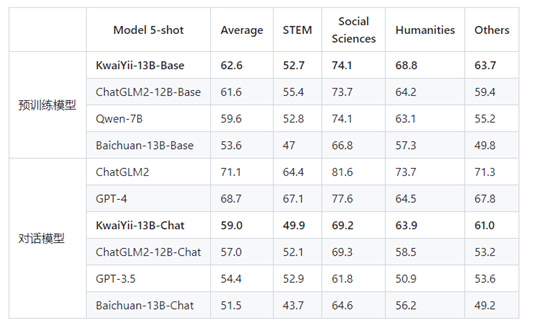
MMLU:可对模型的英文跨学科专业能力进行深入测试。集合了科学、工程、数学、人文、社会科学等领域的57个科目,包含14079道单项选择题。同样是5-shot测试方法。
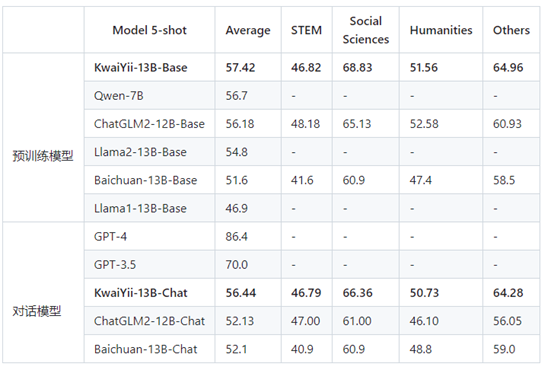
CMMLU:专门用于评估语言模型在中文语境下的知识和推理能力。包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等,共11582道单项选择题。采用5-shot和0-shot方式进行测试。
GSM8K:由OpenAI构建的高中数学应用题数据集,包含8500道高质量的数据,主要目标是对模型的数学推理能力进行评测。其采用8-shot进行评测。
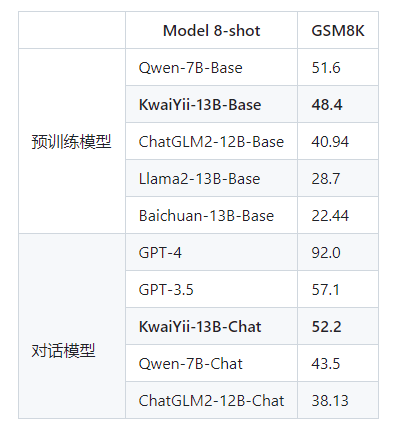
HumanEval:由OpenAI和Anthropic AI一起开发的代码数据集,包含164个原创编程题,涉及语言理解、算法、数学和软件面试等题目。采用0-shot的方式进行评测。
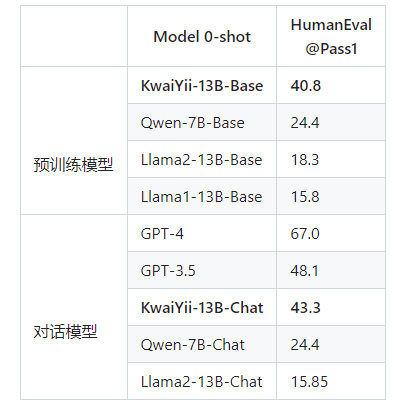
从上述评测结果不难看出,Base、Chat模型在多个测试榜单中的多项性能评测中处于领先地位,突出了模型强大的中文、英文理解能力,以及较好的数理逻辑和代码能力。
目前,快意大语言模型已经开启内测,并为业务团队提供了标准API和定制化项目合作方案,以便在各种业务场景中进行测试和验证。快手AI团队表示,将持续迭代快意大模型,一方面将继续优化模型性能并研发多模态能力,另一方面也在推进更多C端与B端业务场景下的落地。