9月9日,全球人工智能领导者英伟达(NVIDIA)宣布推出NVIDIA TensorRT-LLM,用于提升大语言模型的推理能力。
根据英伟达官方介绍,TensorRT-LLM由TensorRT深度学习编译器组成,包括优化的内核、预处理和后处理,以及用于在NVIDIA GPU上实现突破性的多GPU/多节点通信,这使开发人员能以最高性能和快速自定义功能,而无需深入了解C++或NVIDIA CUDA快速尝试不同的大语言模型。
目前,TensorRT-LLM处于测试阶段,未来几周内会正式发布并开源。
申请地址:https://developer.nvidia.com/tensorrt-llm-early-access
TensorRT-LLM性能评测:
自动生成摘要是大语言模型常用功能之一,在此测试中,TensorRT-LLM 在最新NVIDIA Hopper架构上实现了性能突破。例如,H100在TensorRT-LLM的加持下,将GPT-J 6B大模型的推理能力提升了8倍。

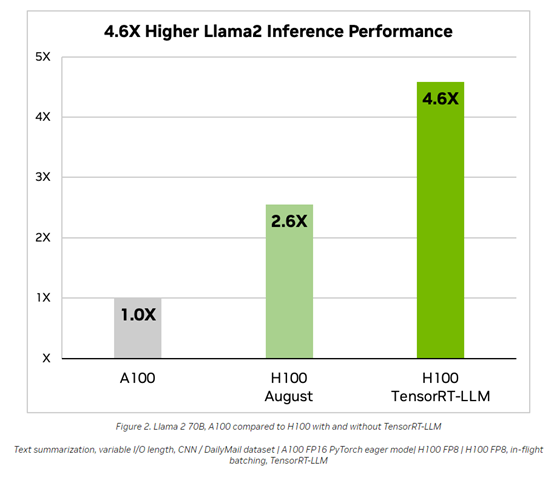
在Meta发布的Llama 2700亿参数大预言模型上,TensorRT-LLM可以将推理性能比 A100 GPU提高 4.6倍。
目前,大语言模型正处于高速发展阶段,一些最大、最先进的语言模型,比如Meta的700亿参数的Llama 2,需要多个GPU配合工作才能达到最佳效果。因此,开发者必须重写并手动将AI模型分割成片段,并在GPU之间协调工作。
TensorRT-LLM采用了张量并行性的方法,其中单个权重矩阵在设备之间分割。这使得可以在大规模上实现高效推理,模型可在通过NVLink连接的多个GPU以及多个服务器之间并行运行,而无需开发者干预或更改模型。
目前,TensorRT-LLM已完全优化好,无需任何修改即可投入使用的模型包括Meta的Llama 2,OpenAI的GPT-2和GPT-3、Falcon、Mosaic MPT、BLOOM等十多种主流大语言模型。
未来,TensorRT-LLM还会持续扩大对大语言模型的支持范围,使得开发人员能以低能效、高效率快速开发属于自己的产品以满足业务需求。