2月16日凌晨,OpenAI发布了首个文生视频模型Sora。Sora基于DALL-E与GPT框架,通用人工智能(AGI)迎来里程碑。
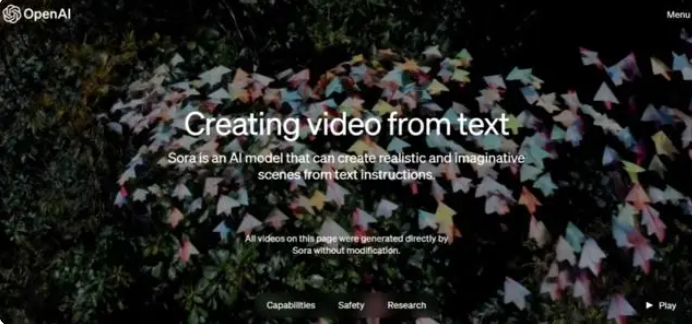
Sora取自日语中的“天空”一词,根据官方介绍,该模型可以生成长达一分钟的视频,同时保持视觉品质并遵循用户提示。它能够生成具有多个角色、特定类型的运动以及精确的主题和背景细节的复杂场景。除了能够仅由文本指令生成视频外,该模型还能够获取现有的静态图像并从中生成视频,并精确地将图像内容动画化。
目前,文生视频领域因为帧间依赖处理、训练数据、算力资源、过拟合等原因,一直无法生成高质量的长视频。
而Sora最大技术突破是,可以在保持质量的前提下,生成1分钟的视频,在业内非常罕见。这也再次展示了OpenAI在大模型领域超强的技术研发能力。
Sora与ChatGPT一样采用的是Transformer架构,并使用了DALL-E 3中的重述技术,是一种为视觉训练数据生成高精准描述性的字幕。所以,Sora在生成视频过程中精准还原用户的文本提示语义。
Sora除了文本生成视频之外,还能根据图像生成视频,并能准确地对图像内容进行动画处理。也能提取视频中的元素,对其进行扩展或填充缺失的帧,功能非常全面。
目前官网上已经更新了48个视频demo,在这些demo中,Sora不仅能准确呈现细节,还能理解物体在物理世界中的存在,并生成具有丰富情感的角色。该模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。
Sora对于需要制作视频的艺术家、电影制片人或学生来说,都带来了无限可能。该模型可以深度模拟真实物理世界,标志着人工智能在理解真实世界场景并与之互动的能力方面实现飞跃,也被认为是实现通用人工智能(AGI)的重要里程碑,通过不断深入研究和发展Sora等先进模型,有望在未来实现更加智能、高效和多样化的视频生成与处理技术。