如今,大多数文生图模型在生成图像方面效果都不太理想。为了解决目前文生图模型在生成内容一致性方面的挑战,英伟达与特拉维夫大学的研究人员联手开发了一款名为ConsiStory的文生图模型(目前尚未开源)。
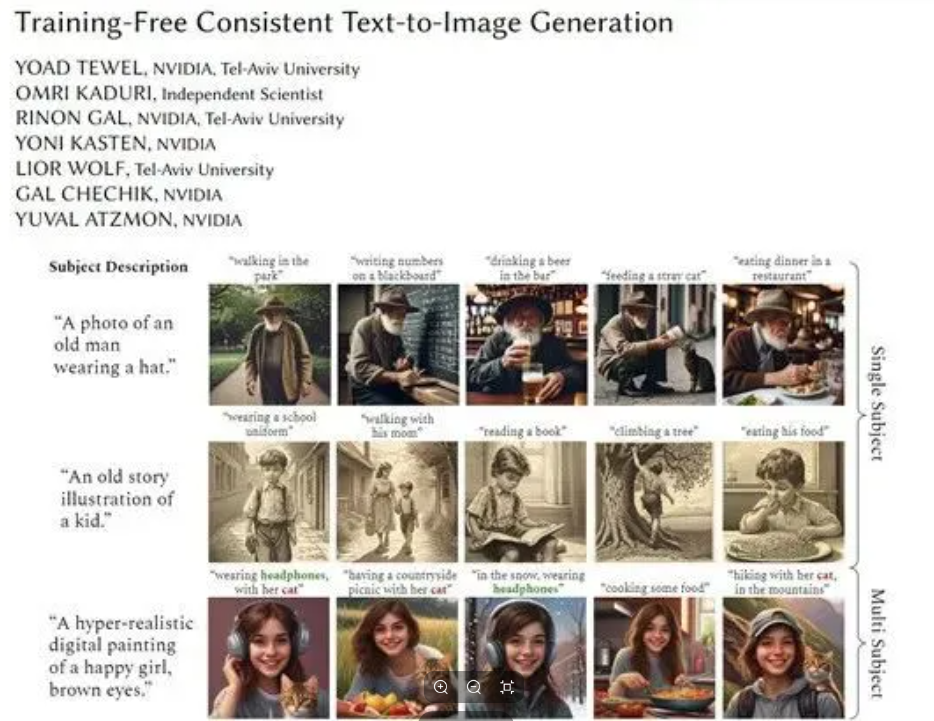
目前,文生图模型在生成内容一致性方面比较差的原因主要有两个:无法识别和定位图像中的共同主体,文生图像模型没有内置的对象检测或分割模块,很难自动识别不同图像中的相同主体;无法在不同图像中保持主体的视觉一致性,即使定位到主体,也很难使不同步骤中独立生成的主体在细节上保持高度相似。
在解决这两种难题上,ConsiStory采用了一种全新的方法,通过主体驱动自注意力(SDSA)和特征注入等核心模块,实现了图像主体的一致性,无需任何训练或调优。
SDSA模块是ConsiStory的核心之一,扩大了扩散模型中自注意力层,允许不同图像中的主体保持一致的外观。通过主体蒙版遮蔽背景区域的敏感信息,不同图像中的主体可以相互"对齐",保持一致性。而特征注入则建立在扩散特征空间的密集对应图上,确保主体相关的纹理、颜色等细节特征在整个批次中互相"对齐",进一步增强了主体间的一致性。
此外,ConsiStory还提供了锚图像和可重用主体功能,锚图像提供了主题信息的参考功能,主要用于引导图像生成过程,确保生成的图像在主题上保持一致。可重用主体是通过共享预训练模型的内部激活,来实现主题一致性的方法。在图像生成过程中,模型会利用预训练模型的内部特征表示来对生成的图像进行对齐,而无需进一步对齐外部来源的图像。这些功能共同助力ConsiStory成为一款无需训练即可生成连贯图片的文生图模型,为AI图像生成领域带来了新的可能性。