随着人工智能的发展,人们已经进入了大语言模型时代。但是时间一长就会发现大语言模型也面临着许多挑战,比如在没有答案的情况下提供虚假信息、从非权威来源创建响应、在用户需要特定的当前响应时提供过时或通用的信息等。RAG的出现,使得其中一些挑战有了解决的方法。它可以重定向大语言模型,从权威的、预先确定的知识来源中检索相关信息。所以说RAG是很重要的。
RAG,就是检索增强生成,是一个对大语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。在大语言模型本就强大的功能基础上,RAG将其扩展为能访问特定领域或组织的内部知识库。RAG是一种在各种情境下都能保持相关性、准确性、实用性的经济高效型改进大语言模型输出的方法。
RAG检索增强生成可以为AIGC领域带来很多的好处和用处,它是一种将新数据引入大语言模型的更加经济高效的方法,可以向用户提供最新最准确信息,有利于增强用户信任度。开发人员也可以借助RAG更高效地测试和改进他们的聊天应用程序。
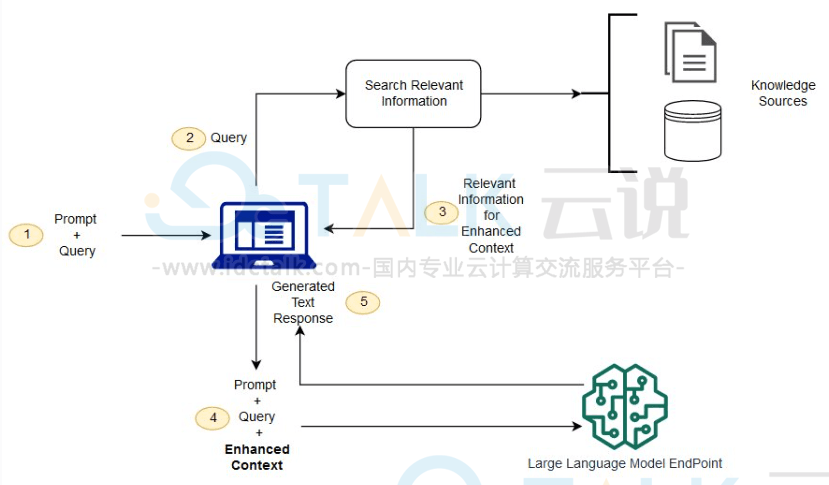
RAG检索增强生成的工作原理:
1、创建外部数据
大语言模型原始训练数据集之外的新数据称为外部数据。它可以来自多个数据来源,例如API、数据库或文档存储库。数据可能以各种格式存在,例如文件、数据库记录或长篇文本。另一种称为嵌入语言模型的AI技术将数据转换为数字表示形式并将其存储在向量数据库中。这个过程会创建一个生成式人工智能模型可以理解的知识库。
2、检索相关信息
用户查询将转换为向量表示形式,并与向量数据库匹配。例如,考虑一个可以回答组织的人力资源问题的智能聊天机器人。如果员工搜索:“我有多少年假?”,系统将检索年假政策文件以及员工个人过去的休假记录。这些特定文件将被退回,因为它们与员工输入的内容高度相关。相关性是使用数学向量计算和表示法计算和建立的。
3、增强大语言模型提示
接下来,RAG模型通过在上下文中添加检索到的相关数据来增强用户输入(或提示)。此步骤使用提示工程技术与大语言模型进行有效沟通。增强提示允许大型语言模型为用户查询生成准确的答案。
4、更新外部数据
下一个问题可能是—如果外部数据过时了怎么办?要维护当前信息以供检索,请移步更新文档并更新文档的嵌入表示形式。可以通过自动化实时流程或定期批处理来执行此操作。这是数据分析中常见的挑战—可以使用不同的数据科学方法进行变更管理。
云计算服务商亚马逊云科技就支持用户的RAG需求。以下是在亚马逊云科技上进行RAG操作的一些实例:
点击进入:亚马逊云科技官网
1、Amazon Bedrock是一项完全托管的服务,提供多种高性能基础模型以及多种功能,用于构建生成式人工智能应用程序,同时简化开发并维护隐私和安全。借助Amazon Bedrock的知识库,用户只需点击几下即可将FM连接到用户的RAG数据来源。矢量转换、检索和改进的输出生成均自动处理。
2、对于管理自己的RAG的组织来说,Amazon Kendra是一项由机器学习提供支持的高精度企业搜索服务。它提供了经过优化的Kendra检索API,用户可以将其与Amazon Kendra的高精度语义排名器一起使用,作为RAG工作流程的企业检索器。
3、Amazon SageMaker JumpStart是一个机器学习中心,包含基础模型、内置算法和预构建的机器学习解决方案,只需单击几下即可轻松部署。用户可以通过参考现有的SageMaker笔记本和代码示例来加快RAG的实施。