近日阿里发布了Qwen2-Math数学系列模型,共有15亿参数、70亿参数和720亿参数三个版本,基于Qwen2 LLM构建,专门用于数学解题的语言模型。
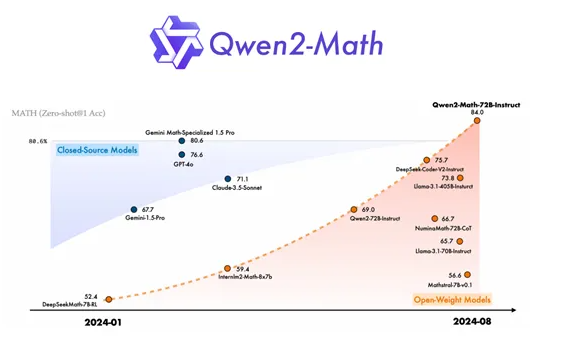
据悉Qwen2-Math在一系列数学基准评测中超越了包括GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro和Llama-3.1-405B在内的最先进的模型。
Qwen2-Math的基础模型使用Qwen2-1.5B/7B/72B为起点,然后在精心设计的高质量数学专用语料库上进行预训练,该语料库包含大规模高质量的数学网络文本、书籍、代码、考试题目以及由Qwen-2模型合成的数学预训练数据。
团队在三个英语数学基准和三个中国数学基准都对Qwen2-Math基础模型进行评估,所有评估均使用Few-shot CoT方式。结果显示,Qwen2-Math基础模型的性能大幅度超越了Llama-3.1-8B/7B/405B全系列。
Qwen2-Math-72B训练的模型在开发指令微调模型方面采用了密集的奖励信号与二元信号的结合,二元信号在此起到指示模型是否正确回答问题的作用,类似于分类任务中的标签,有助于模型在训练过程中进行自我校正。结合信号后,模型通过拒绝采样方法构建了SFT数据集。拒绝采样是一种蒙特卡罗方法,通过在更大范围内按照均匀分布随机采样,然后接受或拒绝采样点来估计复杂问题的概率分布。
这种方法在处理复杂概率分布时特别有用,因为它不要求分布的概率分布函数可逆,从而解决了一些分布难以直接采样的问题。
还使用了GRPO强化学习算法进行优化,这是近端策略优化的一种变体,通过迭代过程进行训练,其中奖励模型会根据策略模型的输出不断更新,以确保策略的持续改进。
阿里使用中英文的数学基准评测对Qwen2-Math-72B-Instruct进行评估。除了常用的GSM8K和Math基准评测,还加入了更具挑战性的考试,例如,OlympiadBench、CollegeMath、中考、高考等。
阿里在预训练和微调数据集上都进行了去污染处理,特别是清洗了对GSM8K、MATH、Aqua、SAT Math、OlympiadBench、College Math等知名基准测试数据集有重叠的正例污染样本,以保证测试效果的准确性、公平性。
目前Qwen2-Math模型仅支持英文,但很快阿里就会推出中英双语版本,敬请期待!