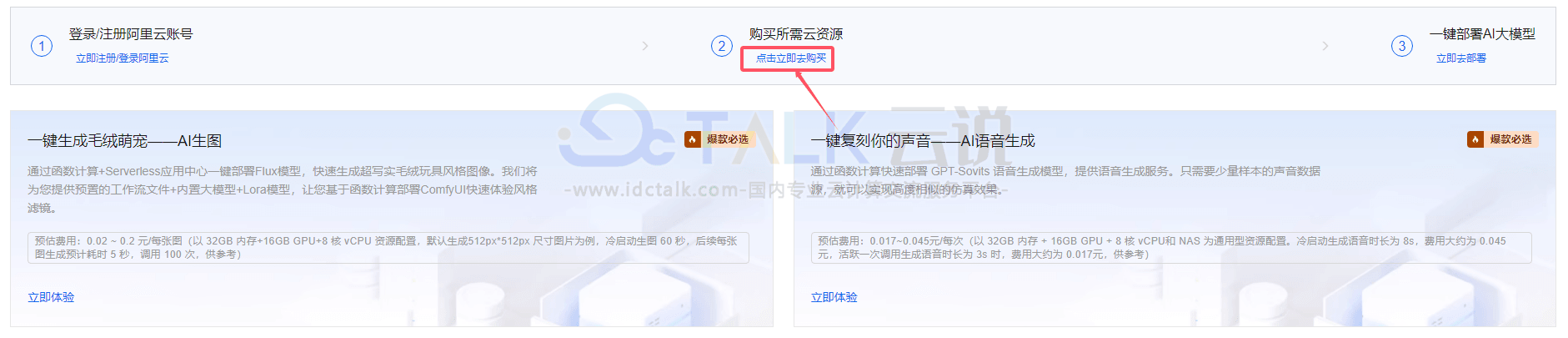
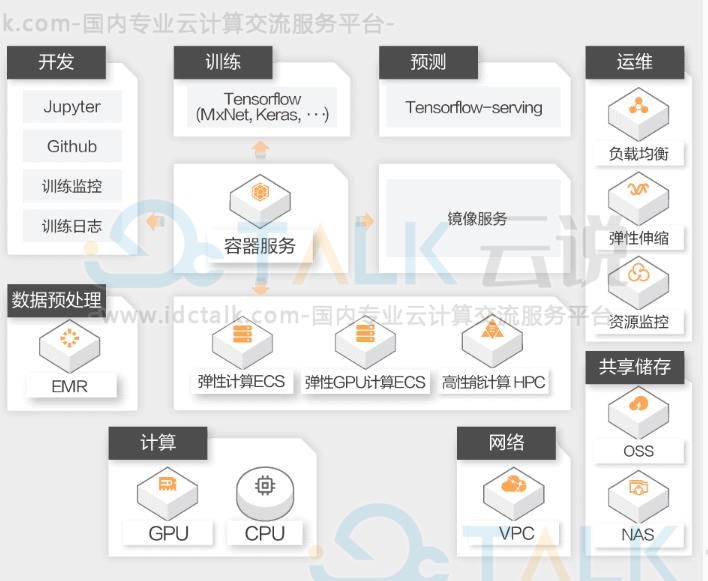
利用阿里云容器服务全面支持GPU和CPU异构资源集群统一管理和调度,与阿里云其他资源服务深度整合,支持机器学习计算的完整生命周期,提供低门槛、开放、高效的深度学习解决方案。
方案架构
1、简单开放
支持主流框架(如Tensorflow、PyTorch,Keras、caffe、MXNet等)和多种环境,屏蔽底层差异并承担非算法相关工作,提供全生命周期方案与一站式管控。
2、高效可靠
极致弹性,提升异构资源使用效率;快速按需构建,加速重复性模型开发;支持多维度监控报警、异常发现与自动修复。
3、深度整合
基于大规模GPU集群部署运维经验,充分利用阿里云计算资源(如ECS、EGS)与数据服务能力(如OSS、NAS、CPFS、EMR等),提供端到端的最佳实践。
4、轻松集成
支持深度学习能力一键服务化发布,与云上应用的轻松集成。
应用场景
如何最小化搭建深度学习环境
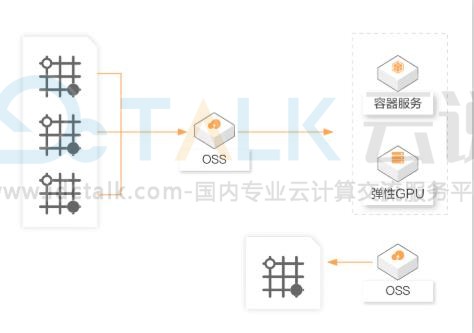
1、强大的GPU计算能力快速反馈训练结果,能根据框架(如Tensorflow)和网络特点调整参数,达到最优训练型性能;
2、能将训练前后的数据放在共享存储服务中,支持一键上传、直接调用、选择备份阶段性数据和训练模型;
3、无缝对接阿里云资源,支持深度学习能力服务化,与云上应用的轻松集成。
GPU调度与监控
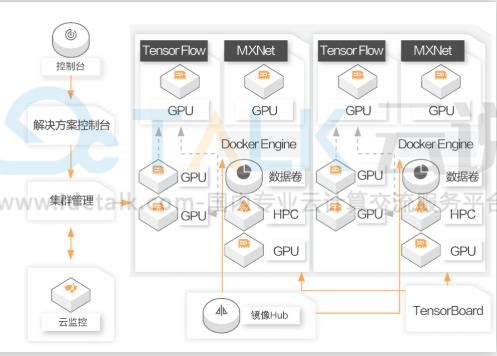
1、通过深度学习解决方案Arena命令行或控制台,提供作业、资源管理一致的体验。
2、多维度的监控、告警和运维平台。
3、增强资源类型抽象、GPU多策略调度能力。
4、支持GPU共享调度,大力优化成本。
5、自动弹性伸缩,削峰填谷。
快捷而完整的方案
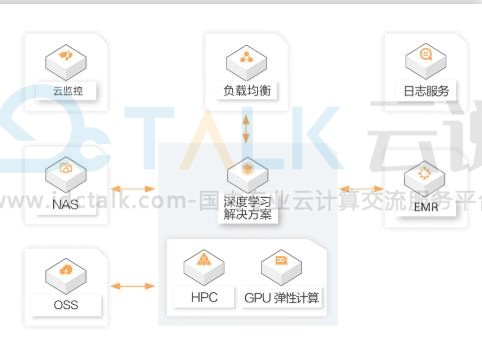
1、可快速构建模型开发、训练和预测的运行环境。
2、集成各种阿里云资源,如存储、网络、负载均衡、弹性、监控、日志、镜像和EMR大数据处理等。
3、提供运行环境搭建、分布式调度、训练任务历史管理、数据存储服务集成等非算法相关的工作支持。
使用指南
1、环境搭建及底层准备
不必关心底资源管理、调度和运维。无需手动记录、管控、配置或部署,告别低使用效率。
2、数据准备
在阿里云OSS中一键上传、直接调用。数据集转换成Tensorflow推荐的TFRecord格式。
3、模型开发
支持Tensorflow/MXNet+Jupyter开发+Tensorboard训练监控+SSH。
4、模型训练
支持基于TensorFlow serving的模型滚动更新、蓝绿发布,负载均衡和弹性伸缩。集成多款产品。