







































最近,清华大学NLP实验室联合上海AI Lab,清华大学电子系及OpenBMB社区提出一种新的结合过程奖励的强化学习方法PRIME。通过这种学习方法,研究人员可以在不依赖任何蒸馏数据和模仿学习的情况下,仅用8张A100,花费一万块钱左右,不到10天时间,就能高效训练出一个数学能力超过GPT-4o、Llama-3.1-70B的7B模型Eurus-2-7B-PRIME。
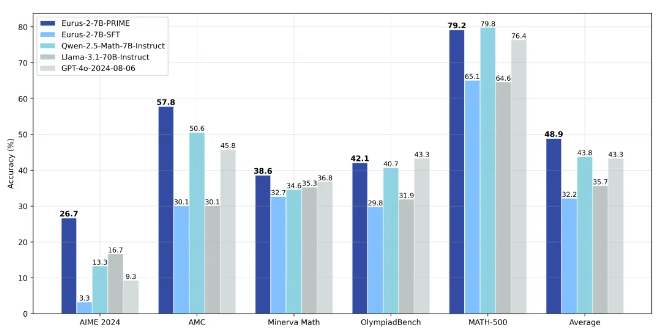
据悉,研究人员利用Qwen2.5-Math-7B-Base作为基座模型,训练出了新模型Eurus-2-7B-PRIME,并在美国IMO选拔考试AIME 2024上的准确率达到26.7%,大幅超越GPT-4o,Llama3.1-70B和Qwen2.5-Math-7B-Instruct,且仅使用了Qwen Math数据的1/10。
PRIME方法介绍:
PRIME算法从隐式过程奖励的思想出发解决这两个问题。隐式过程奖励模型可以仅在输出奖励模型的数据,即答案的最终对错上进行训练,而隐式地建模过程奖励,最终自动训练出一个过程奖励模型,这整个过程都有严格的理论保证。
基于隐式过程奖励模型的这种性质,研究人员指出将其应用于强化学习有三大优势:
1、过程奖励:隐式过程奖励模型能够为每个token提供价值估计,在提供过程奖励的同时无需训练额外的价值模型。
2、可扩展性:隐式过程奖励模型只需结果标签即可在线更新。所以,我们可以结合策略模型采样与结果验证器来直接更新PRM,有效缓解分布偏移与可扩展性问题。
3、简洁性:隐式过程奖励模型本质上就是一种语言模型。在实践中,研究人员发现可以直接用初始的策略模型初始化PRM。
隐式过程奖励解决了PRM在大模型强化学习中怎么用,怎么训,怎么扩展的三大问题,甚至不需要训练额外的奖励模型就可以开始强化学习,易用性和可扩展性极佳。
强化学习是连接已有智能体(大模型)和现实世界(世界模型,具身智能)的桥梁,以及将世界反馈内化为模型智能的路径,将在下一代人工智能的发展中起到重要作用。PRIME算法创新性地将隐式过程奖励与强化学习结合,解决了大模型强化学习的奖励稀疏问题,有望推动大模型复杂推理能力的进一步提升。



