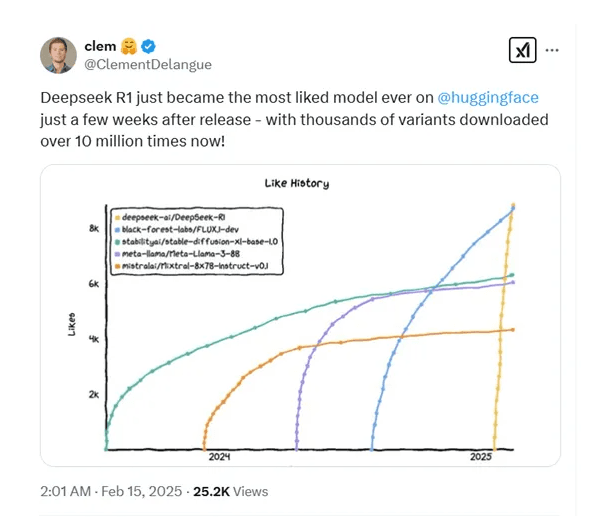
DeepSeek一经发布便火爆全球,被140个国家下载,下载量超过了10000次!全球最大开源平台Hugging Face联合创始人Clément Delangue表示,DeepSeek R1在发布仅仅几周后,就成为了Hugging Face平台上有史以来最受欢迎的模型。
过年期间,DeepSeek发布了R1版本,在美国AIME 2024测试中R1拿下79.8分,超过了OpenAI的o1模型的79.2分;在MATH-500,R1为97.3分,同样超过了o1的96.4分;在SWE-bench Verified,R1为49.2分再次超过了o1的48.9分。而在代码测试Codeforces中,R1仅比o1模型低0.3分;MMLU低1分;GPQA低4.2分,整体性能与o1模型相当。但价格方面o1模型每100万tokens的输入是15美元,R1是0.14美元,比GPT-4o-mini价格还要低成本猛降90%。输出价格则更是低的离谱,o1每100万tokens输出是60美元,R1只有2.19美元,降低了27倍左右。
在DeepSeek宣布开源R1后,迅速在全球领域走红,还对美国科技股造成重创一直火爆至今。
其实DeepSeek最开始开发的是R1-Zero模型,通过纯强化学习训练,不依赖于任何监督学习数据。该模型以DeepSeek-V3-Base为基础,采用了GRPO算法进行训练,通过采样一组输出并计算其相对优势,从而优化模型的策略,避免了传统强化学习中需要与策略模型同规模的评估模型,大大降低了训练成本。
在训练过程中,R1-Zero展现出了一系列强大的推理行为,例如,自我验证、反思和生成长推理链等。这些行为并非人为植入,而是模型在强化学习过程中自然涌现的结果。例如,在AIME 2024数学竞赛中,R1-Zero的Pass 1得分从初始的15.6%提升至71.0%,通过多数投票进一步提升至86.7%,与OpenAI-o1-0912模型相当。这一结果证明了纯强化学习在提升模型推理能力方面的巨大潜力。
但是R1-Zero也存在一些问题,如可读性差和语言混用等。所以,DeepSeek又开发出了R1模型。R1在R1-Zero的基础上进行了改进,引入了冷启动数据和多阶段训练流程,以提升模型的推理能力和可读性。
冷启动阶段是R1训练流程的起点,也是整个训练策略中最重要的一环。与R1-Zero直接从基础模型开始强化学习不同,R1引入了少量高质量的长CoT数据作为冷启动数据,为模型提供一个更加稳定和优化的起点,从而在后续的强化学习过程中更好地发展推理能力。
冷启动数据:
冷启动数据的一个关键特点是其对可读性的优化。与R1-Zero生成的推理过程相比,冷启动数据更加注重语言的清晰性和逻辑性。
例如,团队设计了一种特定的输出格式,即在每个回答的末尾添加一个总结,并用特殊标记将推理过程和总结区分开来。这种格式不仅使模型的输出更加易于理解,也为后续的强化学习提供了一个明确的结构框架。
多阶段训练流程:
这一流程的设计目标是通过逐步优化和调整,使模型在推理能力上达到更高的水平,同时在其他任务上也表现出色。
第一阶段:推理导向的强化学习。
第二阶段:拒绝采样与监督微调。
第三阶段:全场景强化学习。