DeepSeek-R1是DeepSeek的一种高阶推理模式,专为复杂推理任务设计,强化在数学、代码生成和逻辑推理领域的性能,用低成本以及更小的算力规模实现了美国顶级AI模型的效果。本文就来为大家介绍一下使用百度智能云GPU云服务器来实现DeepSeek的本地部署。
一、购买百度智能云GPU服务器
百度智能云GPU服务器是配备GPU的云端服务器,可以为机器学习、高性能计算、图形图像渲染等计算密集型应用提供加速处理能力,提供丰富的产品类型。此次选择的是计算型GN5服务器,推荐最低配置16核CPU,64GB内存,Nvidia Tesla A10单卡24G显存,搭配100GB SSD数据盘,安装Windows Server 2022系统。
百度智能云GPU云服务器方案推荐
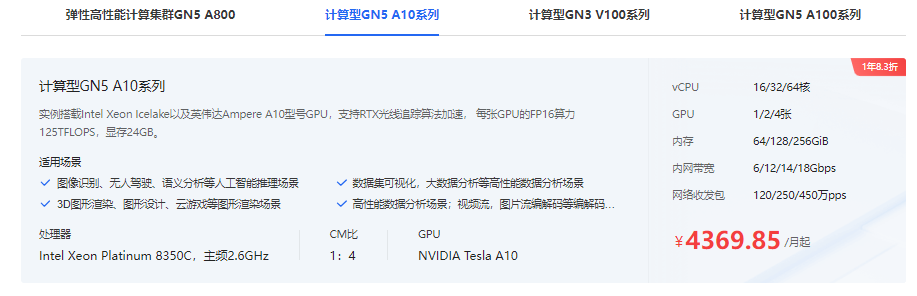
《点击进入官网选购》
1、登录控制台,按需购买云服务器,比如选择配置为16核64G带1张A10 GPU卡的实例。
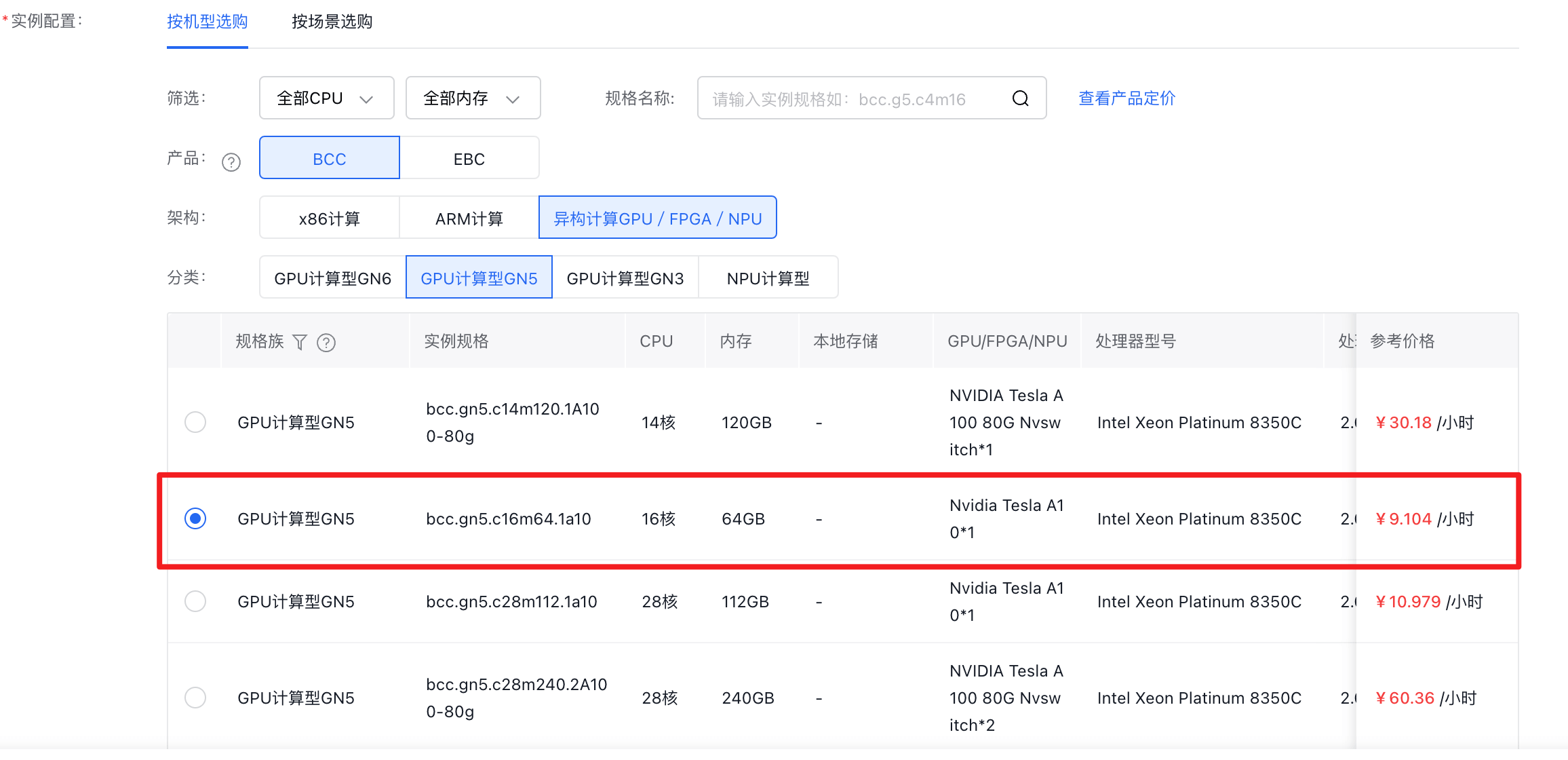
2、安装操作系统
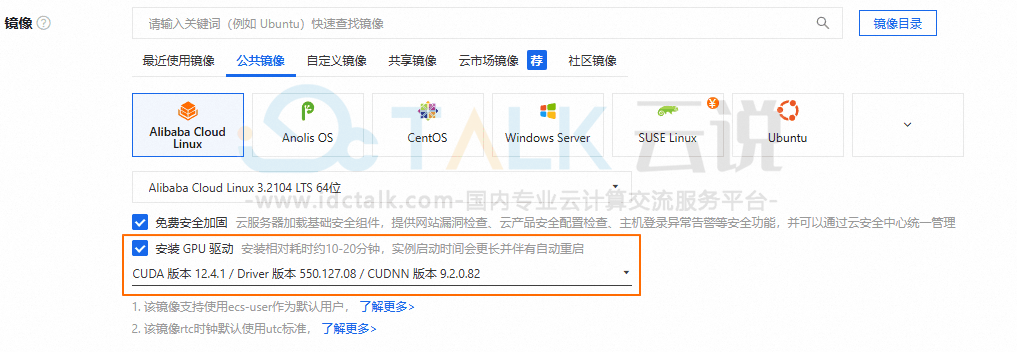
- 选择Windows公共镜像,支持Windows2019及以上版本,本教程选择Windows2022。

- 通过VNC登录实例,安装GPU驱动程序。
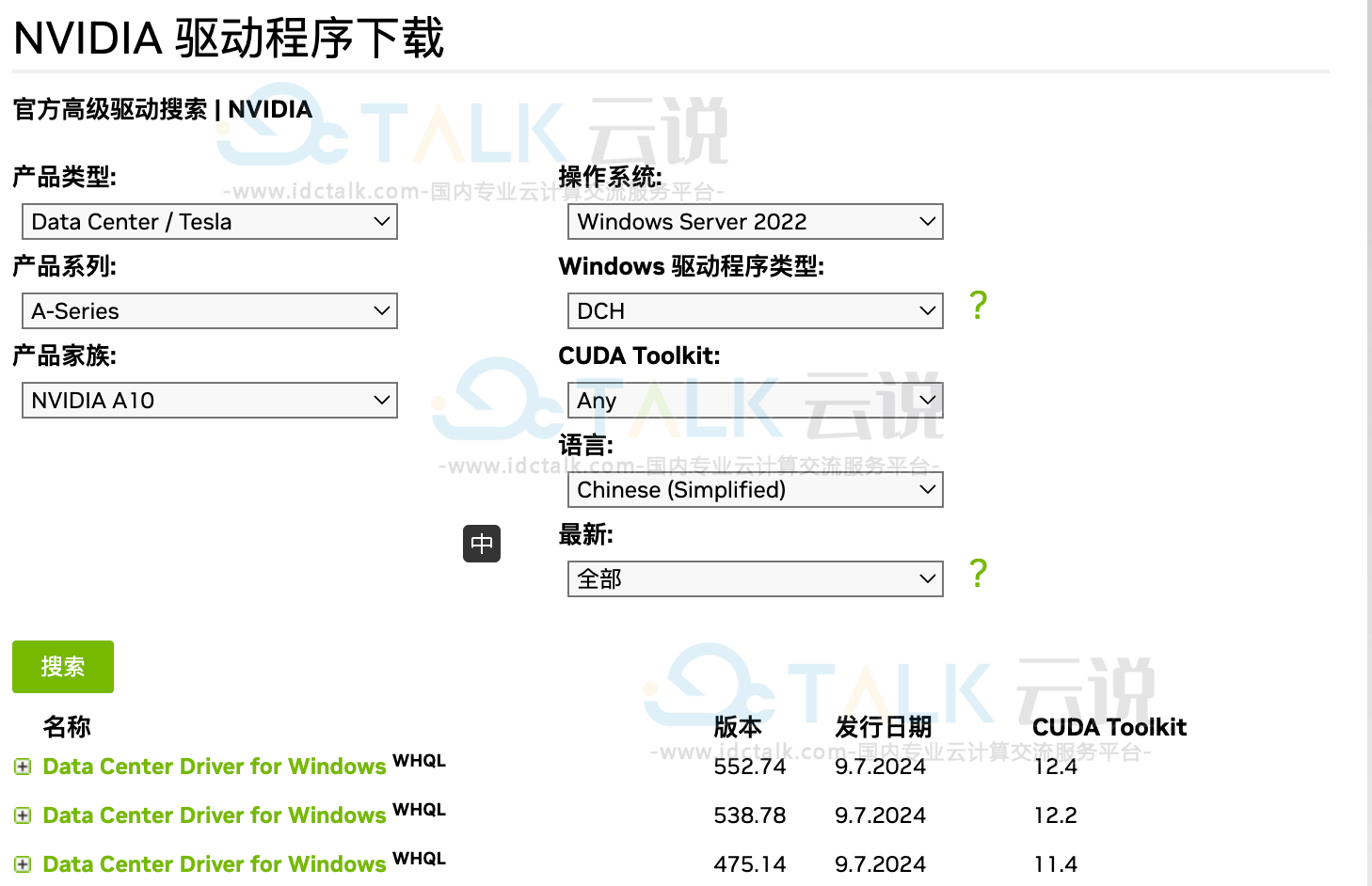
3、通过浏览器进入NVIDIA官方驱动下载地址,选择相应驱动下载进行安装,本教程选择538.78,CUDA版本为12.2。
二、安装Ollama
1、indows客户端安装。
- 从官方下载地址(https://ollama.com/download/windows)下载,保证最新版本,下载好后直接运行安装。
- 安装完毕会自动运行,右下角可以看到这个图标:
- 打开windows PowerShell或在CMD命令行终端,输入ollama命令,回车,即可显示ollama命令的使用帮助。

三、下载DeepSeek模型
DeepSeek是一款由国内人工智能公司研发的大型语言模型,拥有强大的自然语言处理能力,能够理解并回答问题,还能辅助写代码、整理资料和解决复杂的数学问题。目前在全球范围内引发广泛关注。
相关推荐:
DeepSeek包含1.5b,7b,8b,14b,32b,70b,671b不同参数级别,参数越大,精度越高,模型效果越好,根据自己的GPU显存大小选择不同的参数级别。由于A10 GPU只有24G显存,本文可以安装14b模型版本。
执行如下命令,ollama会自动下载模型并加载运行,出现success提示时,说明模型加载完成,可以愉快的跟大模型交流了。
ollama run deepseek-r1:14b
四、配置远程访问
Ollama启动的默认地址为http://127.0.0.1:11434,本文通过设置环境变量OLLAMA_HOST来修改默认监听地址和端口,这往往对用户需要远程调用API时非常有用。
1、停止ollama服务
右下角这个图标,右键选择退出。
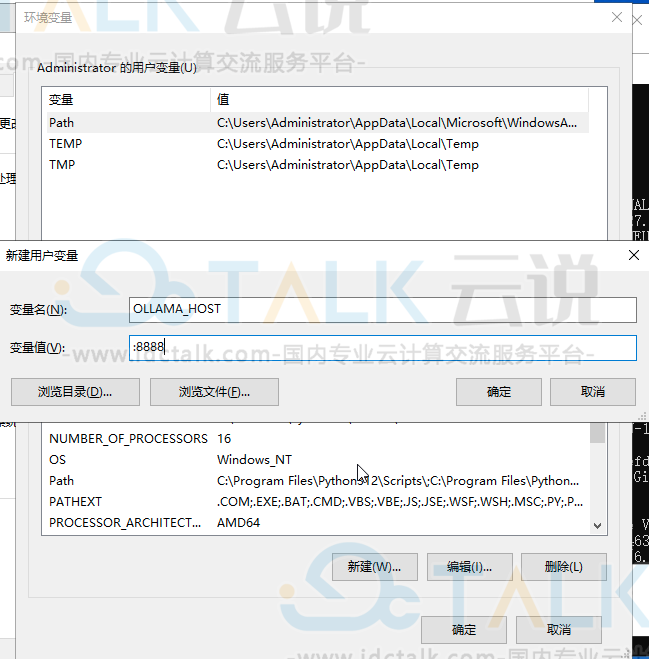
2、设置环境变量OLLAMA_HOST,OLLAMA_ORIGINS
右键"此电脑>属性>高级系统设置>环境变量>Administrator的用户变量>新建用户变量"。
|
环境变量名
|
变量值
|
说明
|
|
OLLAMA_HOST
|
:8888
|
根据业务需要更改Ollama的监听地址和端口
|
|
OLLAMA_ORIGINS
|
*
|
允许跨域访问,方便浏览器调用Ollama的API
|
设置环境变量,表示监听在0.0.0.0:8888上。
|
环境变量名
|
变量值
|
说明
|
|
OLLAMA_HOST
|
:8888
|
根据业务需要更改Ollama的监听地址和端口
|
|
OLLAMA_ORIGINS
|
*
|
允许跨域访问,方便浏览器调用Ollama的API
|
3、设置完毕环境变量,打开新的powershell或者CMD命令行终端,重新启动ollama服务并加载模型。
ollama run deepseek-r1:14b五、DeepSeek模型应用
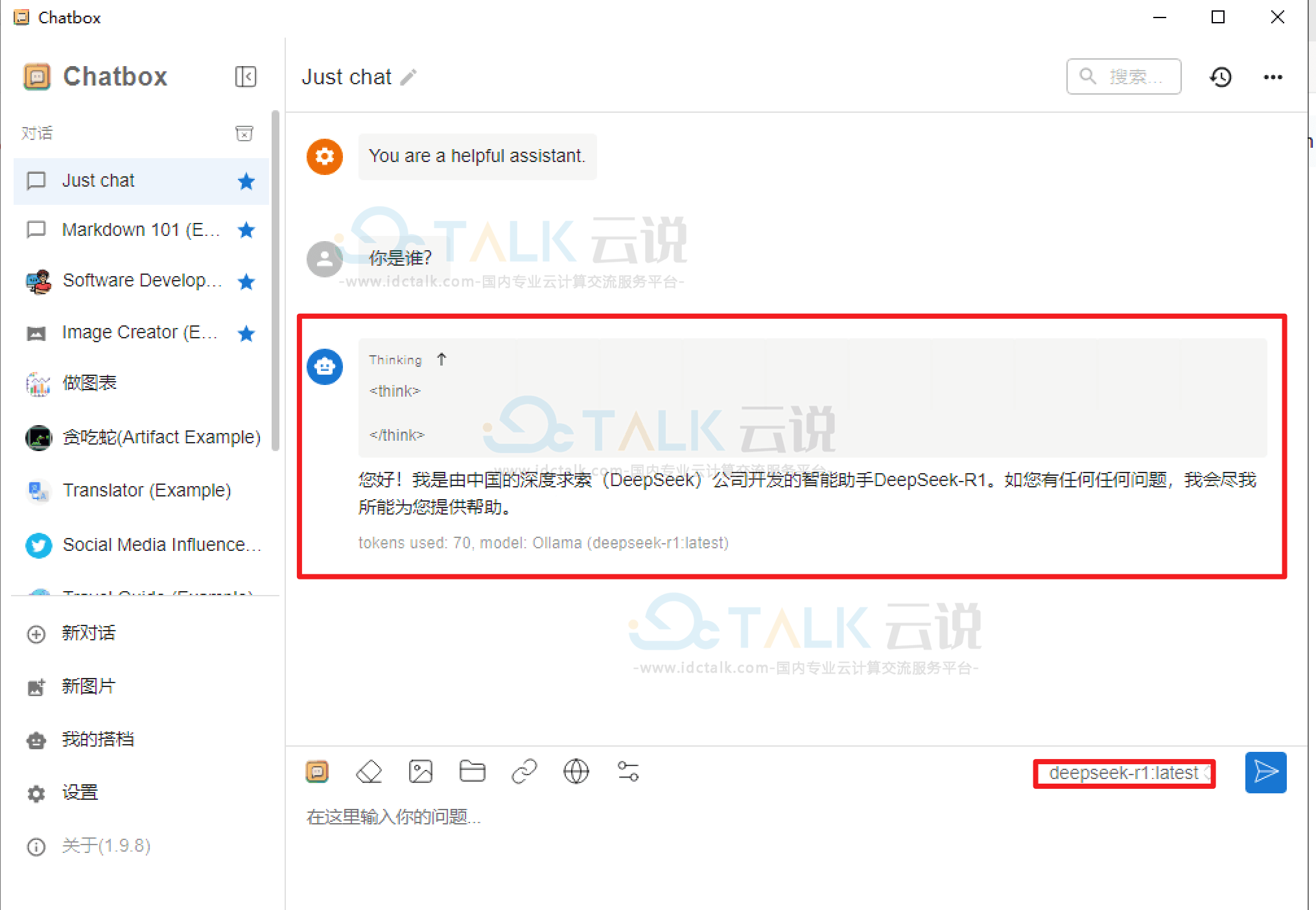
模型部署完成后,我们可以使用命令行或者API与模型进行对话,但在交互上总是不太方便,我们可以使用ChatBox工具,通过交互界面与模型对话。
1、使用ChatBox对话
a.从ChatBox官网(https://chatboxai.app/zh)上下载最新工具,安装完毕后,来配置本地模型。
注:如果chatbox和ollama运行在同一服务器上,ollama地址可以选择本地127.0.0.1地址,否则需要输入实际地址。
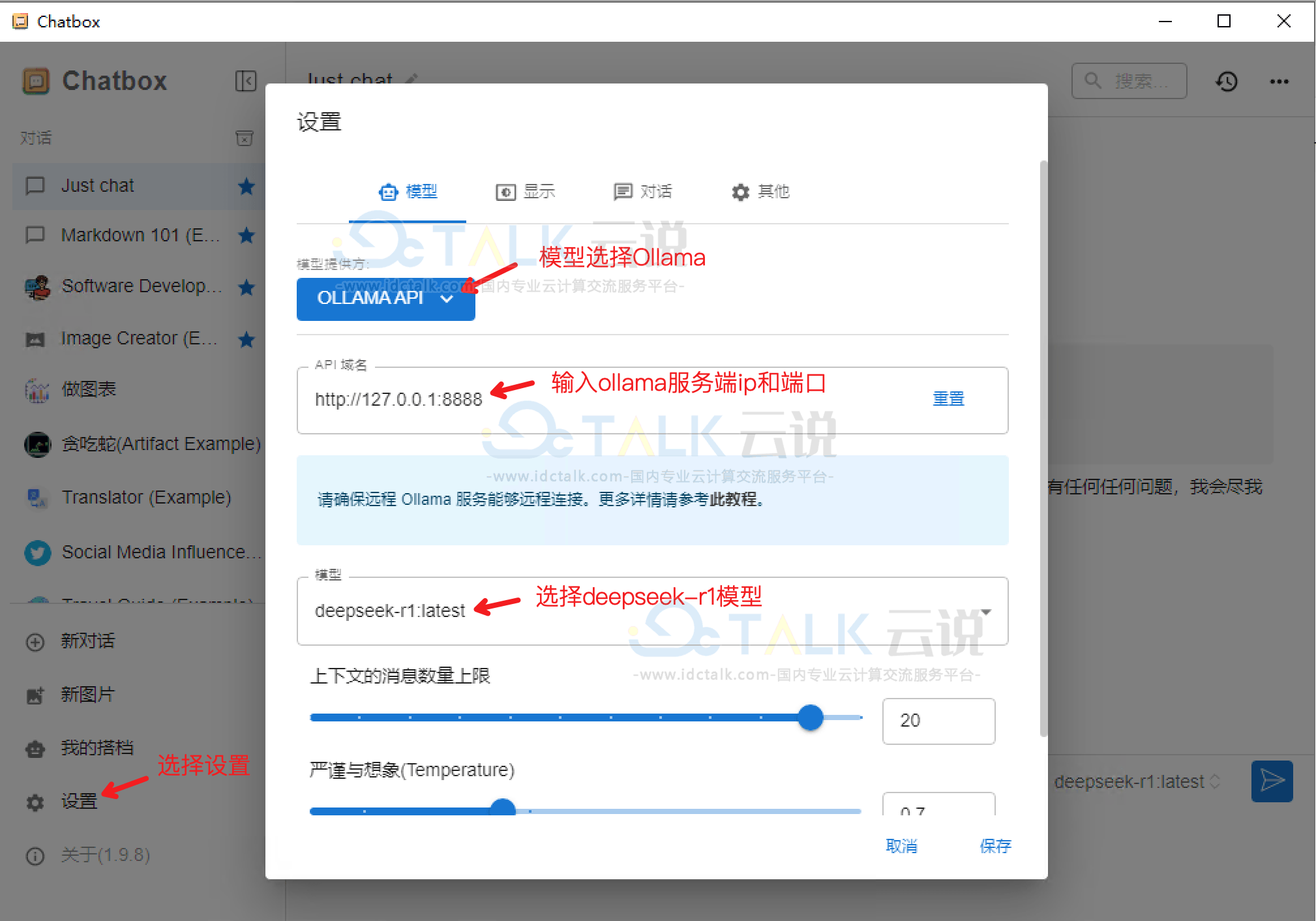
b.与模型对话
2、API调用
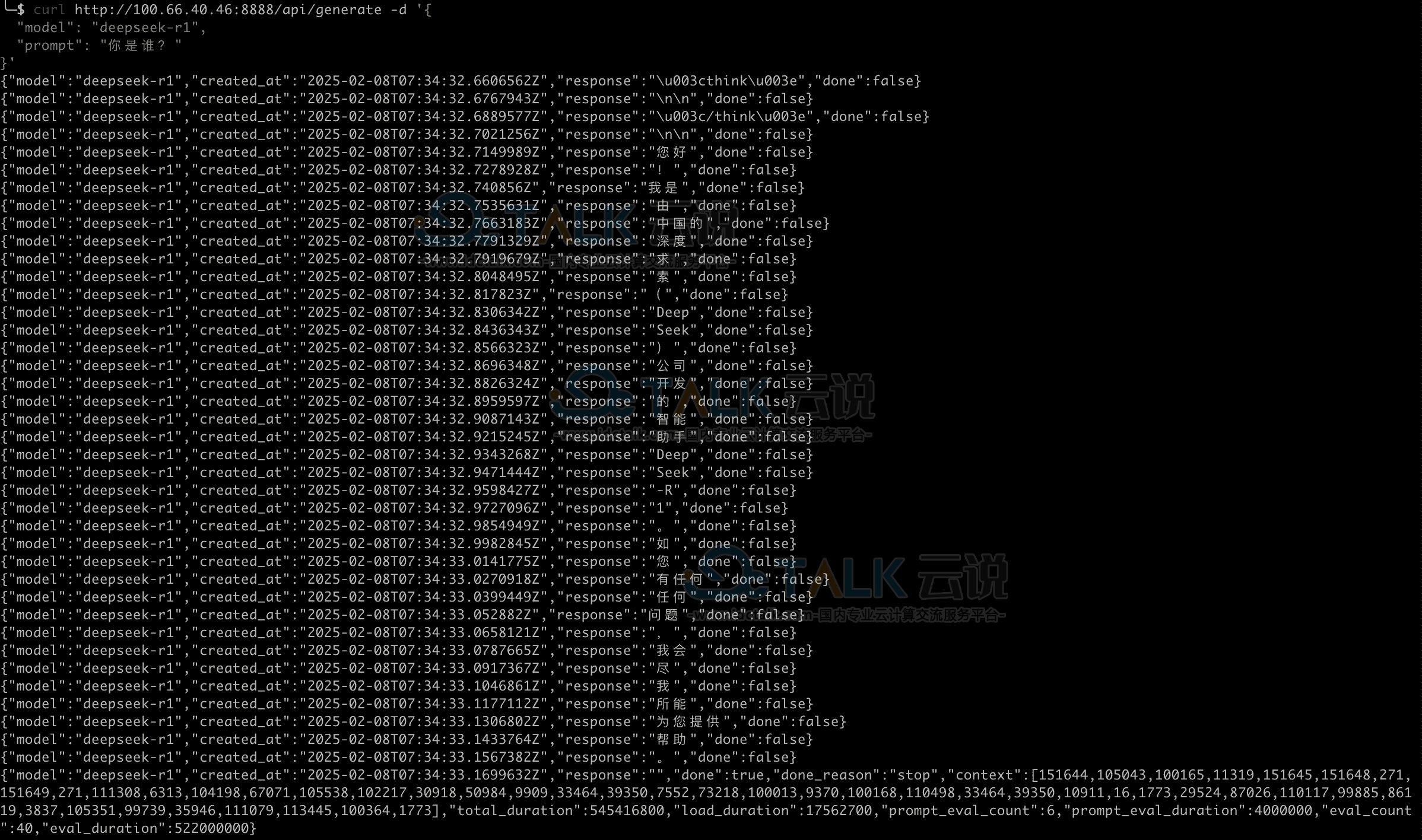
a.开启远程连接之后,用户就可以远程调用API了,示例如下,10.10.3.10替换为用户服务器IP。
b.流式输出: