DeepSeek是一款由杭州深度求索人工智能基础技术研究有限公司开发的人工智能模型,免费体验与全球领先AI模型的互动交流。为了更好的了解DeekSeek系列模型在言犀平台上进行模型部署,本文将为大家介绍一下京东云使用言犀一键部署DeepSeek系列模型教程,仅供参考。
DeepSeek系列模型:
- DeepSeek-V3是幻方量化旗下AI公司深度求索(DeepSeek)研发并开源的一款高性MoE模型,模型总参数量为671B,每个token激活的参数量为37B。在14.8T Token上进行了预训练,在长文本、代码、数学、百科、中文能力上表现优秀。
- DeepSeek-R1是DeepSeek发布的高性能AI推理模型,参数量660B,在数学、代码、自然语言推理等任务上,其性能与OpenAI的o1正式版相当。
- DeepSeek同时开源了若干参数量较小的蒸馏模型(DeepSeek-R1-Distill)。
一、购买京东云言犀AI开发计算平台
京东云言犀AI开发计算平台是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据准备、模型开发、模型训练、模型部署在内的AI开发全链路服务,内置多种开源模型和数据集,为用户提供低门槛、高性价比的云原生AI工程化能力,助力AI算法和应用的价值提升。
1、进入言犀AI开发计算平台产品详情页面,点击“立即购买”。

进入控制台后,完成授权准备。
2、在部署时,LLM模型因为模型较大,资源性能要求较高,需要独占计算卡进行部署,建议提前准备好专属资源节点
功能路径:专属资源组-创建资源组-创建节点。


3、购买资源
节点规格选择建议:
- 部署DeepSeek-V3/R1,推荐使用cap.hc.p5h20.46xlarge
- 部署DeepSeek-R1-Distill-Qwen-1.5B/7B/8B,推荐使用cap.p.n3a30.4xlarge
| 模型 | 总参数 | 上下文长度 | 显存计算资源 | 推理资源推荐 |
|---|---|---|---|---|
| DeepSeek-V3 | 671B | 128K | 8*96G | cap.hc.p5h20.46xlarge |
| DeepSeek-R1 | 671B | 128K | 8*96G | cap.hc.p5h20.46xlarge |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | 24G | cap.p.n3a30.4xlarge | |
| DeepSeek-R1-Distill-Qwen-7B | 7B | 24G | cap.p.n3a30.4xlarge | |
| DeepSeek-R1-Distill-Llama-8B | 8B | 24G | cap.p.n3a30.4xlarge | |
| DeepSeek-R1-Distill-Qwen-14B | 14B | 48G | cap.p.n3a30.8xlarge | |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 96G | cap.p.n3a30.16xlarge | |
| DeepSeek-R1-Distill-Llama-70B | 70B | 2*96G | cap.p.n3a30.32xlarge |

4、进入平台控制台,查看模型。
基础模型平台预置了诸多基础大模型,在实际任务场景下,充分了解并选择合适的基础模型,对实际任务目标的达成会起到事半功倍的效果。
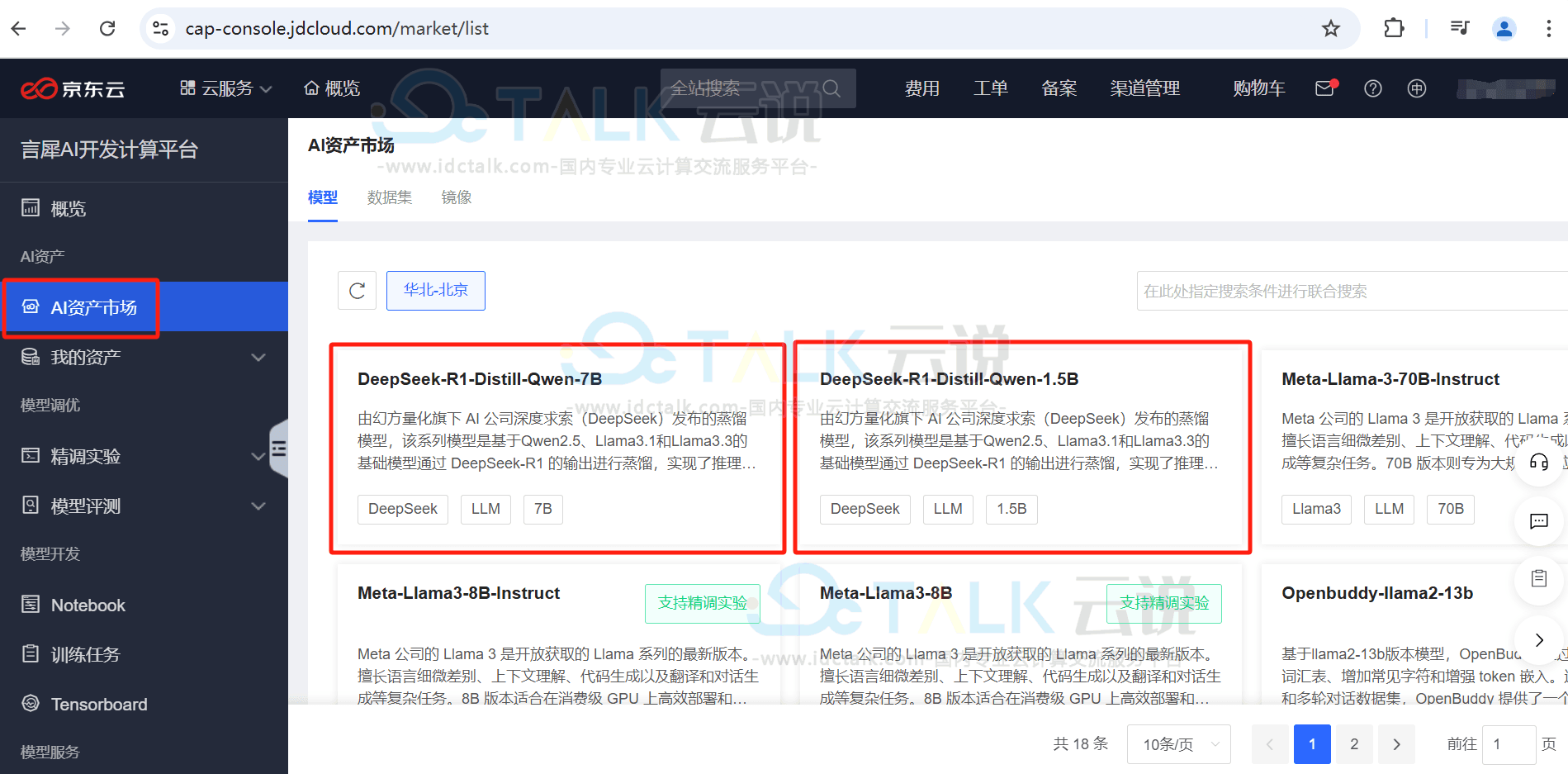
在“AI资产市场/模型”中,提供DeepSeek开源的多个版本,如DeepSeek-R1-Distill-Qwen-1.5B:
二、部署DeepSeek模型
对于我们已经确认的模型,需要部署到相应的服务资源上提供推理调用服务。在部署时平台将自动适配预置推理框架,实现一键部署,我们仅需指定使用的专属资源组和对应的节点规格。
1、创建服务
功能路径:在线服务-部署


一般来说,LLM模型的部署时长在几分钟至几十分钟不等。部署完成后,状态将会变为运行中,运行中的模型可被调用,提供推理服务。
- 部署DeepSeek-V3,首次部署涉及模型文件下载,耗时实测一小时以内;
- 部署DeepSeek-R1系列,首次部署耗时,实测20分钟以内;

2、测试服务
我们可对运行中的服务进行调用测试,查看推理效果。
功能路径:在线服务-服务列表|服务名称-在线调试


- a./v1/models get先用这个接口获取到部署好的模型名称
- b./v1/chat/completions post会话接口
参数
{
"model":"llm",
"temperature": 0.3,
"max_tokens":300,
"messages": [{"role": "user", "content": "中国的首都是哪里?"}],
"stream":false
}
c./v1/completions post生成接口
参数
{
"model": "llm",
"prompt": "夏天是我最喜欢的季节,",
"max_tokens": 500,
"temperature": 0.3,
"stream":false
}
相关推荐: