DeepSeek爆火,从个人到企业,各类DeepSeek应用需求激增。京东云目前已正式上线DeepSeek-R1模型,支持公有云在线部署、专混私有化实例部署两种模式,用户可以按需进行部署。本文就以京东云GPU云主机为例,为大家介绍一下如何在GPU云主机上部署DeepSeek-R1,教程仅供参考。
一、创建京东云GPU云主机
京东云GPU云主机是提供GPU算力的弹性计算服务,具有超强的并行计算能力,正在深度学习、科学计算、图形图像处理、视频编解码等场景广泛使用。京东云GPU云主机,为用户提供触手可得的算力,有效缓解计算压力,提升用户的业务效率,并可弹性扩展,助用户快速构建异构的计算应用。
京东云GPU云主机目前提供丰富的产品规格套餐,包括标准型、虚拟化型两类GPU实例,提供NVIDIA A30、A10、V100、P40等多款GPU规格,用户可以按需选购。

《点击进入官网选购》
1、进入京东云官网,注册账号并登录。
2、选择“产品”>“弹性计算”,点击“GPU云主机”。
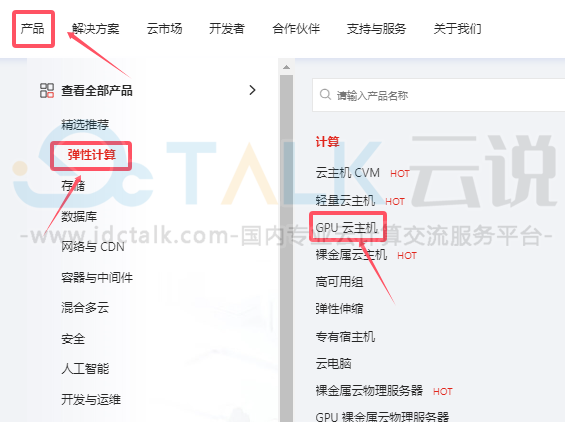
3、在以下界面点击“立即购买”。

4、基于用户的实际业务需求选择云主机计费模式、地域、可⽤区、CPU架构、系统镜像及系统版本,本文选择Linux系统。
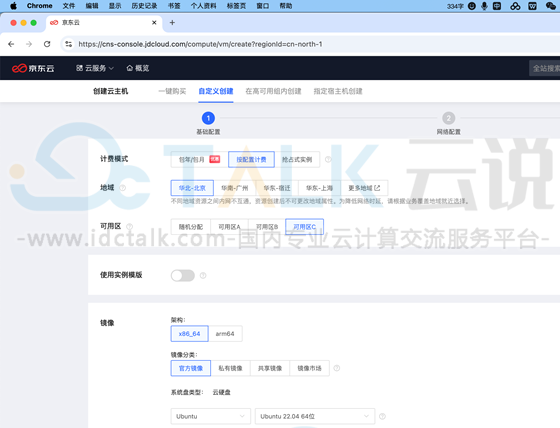
5、选择GPU实例规格类型,可选自动安装GPU驱动、或云主机运行成功后单独安装GPU驱动,本文选择单独安装GPU驱动。
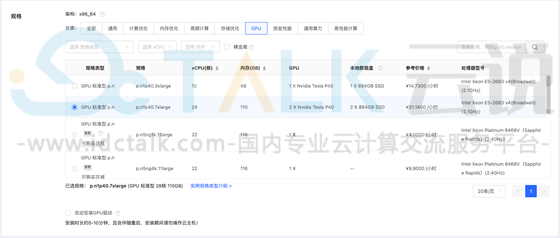
6、自定义云盘类型及大小,点击“下一步”。
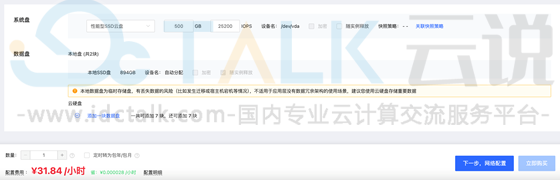
7、自定义云主机网络、安全组、弹性公网IP,安全组需要允许客户端访问11434端口,点击“下一步”。
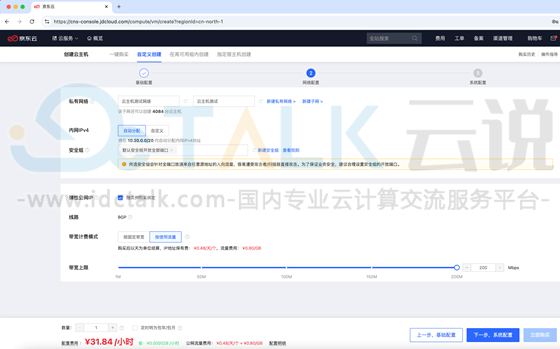
8、自定义主机密码、主机名称等信息,点击“立即购买”。
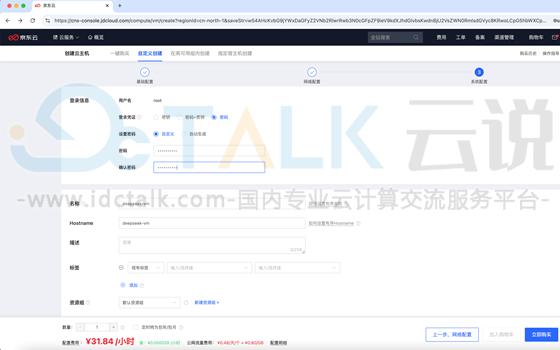
9、勾选已阅读并同意并确认开通。

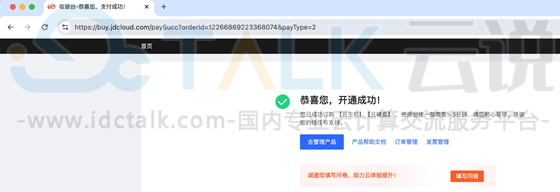
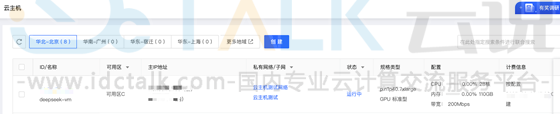
10、京东云GPU云主机创建完成,然后在云主机控制台验证主机运行成功。
11、安装GPU显卡驱动
使⽤SSH⼯具远程连接到实例,安装显卡驱动。
root@deepseek-vm:~# apt update
root@deepseek-vm:~# ubuntu-drivers devices
== /sys/devices/pci0000:00/0000:00:0a.0 ==
modalias : pci:v000010DEd00001B38sv000010DEsd000011D9bc03sc02i00
vendor : NVIDIA Corporation
model : GP102GL [Tesla P40]
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : nvidia-driver-550 - distro non-free recommended
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-418-server - distro non-free
driver : nvidia-driver-545 - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-535 - distro non-free
driver : nvidia-driver-390 - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
root@deepseek-vm:~# apt install nvidia-driver-550 -y #通过ubuntu仓库安装推荐的驱动版本或使用其它方式安装显卡驱动
root@deepseek-vm:~# reboot #重启服务器以使显卡驱动生效
root@deepseek-vm:~# nvidia-smi #重启后验证驱动及显卡状态(当前演示主机为两块NVIDIA Tesla P40显卡)
Thu Feb 6 16:45:28 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.120 Driver Version: 550.120 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P40 Off | 00000000:00:09.0 Off | 0 |
| N/A 24C P8 9W / 250W | 0MiB / 23040MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Tesla P40 Off | 00000000:00:0A.0 Off | 0 |
| N/A 23C P8 9W / 250W | 0MiB / 23040MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
二、部署Ollama
Ollama是一个开源的LLM(大型语言模型)服务工具,用于简化和降低在本地的部署和使用门槛,可以快速在本地环境部署和管理LLM运行环境。
1、下载Ollama,下载地址:https://ollama.com/。
2、下载⼆进制安装包
Ollama可以运⾏在Windows、Linux以及MacOS,官⽅均提供对应的安装⽂件,⽣产环境对稳定性要求⽐较⾼因此会通常使⽤Linux系统。
3、部署Ollama
ollama/docs/linux.md at main·ollama/ollama·GitHub
root@deepseek-vm:/usr/local/src# tar -C /usr -xzf ollama-linux-amd64.tgz #解压安装文件
root@deepseek-vm:/usr/local/src# ollama serve 测试启动 Ollama
Couldn't find '/root/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 AAAA.....
2025/02/06 17:08:47 routes.go:1187: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-02-06T17:08:47.465+08:00 level=INFO source=images.go:432 msg="total blobs: 0"
time=2025-02-06T17:08:47.465+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 0"
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] POST /api/pull --> github.com/ollama/ollama/server.(*Server).PullHandler-fm (5 handlers)
[GIN-debug] POST /api/generate --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (5 handlers)
[GIN-debug] POST /api/chat --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (5 handlers)
[GIN-debug] POST /api/embed --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (5 handlers)
[GIN-debug] POST /api/embeddings --> github.com/ollama/ollama/server.(*Server).EmbeddingsHandler-fm (5 handlers)
[GIN-debug] POST /api/create --> github.com/ollama/ollama/server.(*Server).CreateHandler-fm (5 handlers)
[GIN-debug] POST /api/push --> github.com/ollama/ollama/server.(*Server).PushHandler-fm (5 handlers)
[GIN-debug] POST /api/copy --> github.com/ollama/ollama/server.(*Server).CopyHandler-fm (5 handlers)
[GIN-debug] DELETE /api/delete --> github.com/ollama/ollama/server.(*Server).DeleteHandler-fm (5 handlers)
[GIN-debug] POST /api/show --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (5 handlers)
[GIN-debug] POST /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).CreateBlobHandler-fm (5 handlers)
[GIN-debug] HEAD /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).HeadBlobHandler-fm (5 handlers)
[GIN-debug] GET /api/ps --> github.com/ollama/ollama/server.(*Server).PsHandler-fm (5 handlers)
[GIN-debug] POST /v1/chat/completions --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (6 handlers)
[GIN-debug] POST /v1/completions --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (6 handlers)
[GIN-debug] POST /v1/embeddings --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (6 handlers)
[GIN-debug] GET /v1/models --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (6 handlers)
[GIN-debug] GET /v1/models/:model --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (6 handlers)
[GIN-debug] GET / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
[GIN-debug] GET /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] GET /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
[GIN-debug] HEAD / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
[GIN-debug] HEAD /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] HEAD /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
time=2025-02-06T17:08:47.466+08:00 level=INFO source=routes.go:1238 msg="Listening on 127.0.0.1:11434 (version 0.5.7)"
time=2025-02-06T17:08:47.466+08:00 level=INFO source=routes.go:1267 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 cuda_v11_avx cuda_v12_avx rocm_avx]"
time=2025-02-06T17:08:47.466+08:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2025-02-06T17:08:48.193+08:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-a9100a2b-3c31-b1b4-0891-c11584b5a57f library=cuda variant=v12 compute=6.1 driver=12.4 name="Tesla P40" total="22.4 GiB" available="22.2 GiB"
time=2025-02-06T17:08:48.193+08:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-d652ebd4-0571-78b9-bf01-9a8d1da592e5 library=cuda variant=v12 compute=6.1 driver=12.4 name="Tesla P40" total="22.4 GiB" available="22.2 GiB"
4、验证Ollama是否正在运行
新建另外⼀个终端、验证Ollama是否正在运⾏:root deepseek-vm:~#ollama-v ollama version is 0.5.7
5、添加Ollama作为启动服务
新建账户和组、名称都叫ollama,以普通账户的身份运⾏Ollama服务、并指定监听在0.0.0.0:11434,以⽅便外部客户端访问。
root@deepseek-vm:~# useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
root@deepseek-vm:~# usermod -a -G ollama root
创建/etc/systemd/system/ollama.service 启动文件:
root@deepseek-vm:~# vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
Environment="OLLAMA_HOST=0.0.0.0:11434"
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=default.target
#Ctrl+C退出2.3步骤运行的ollama服务、并通过service文件启动服务:
root@deepseek-vm:~# systemctl daemon-reload
root@deepseek-vm:~# systemctl enable ollama
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
root@deepseek-vm:~# systemctl start ollama.service #启动ollama服务
root@deepseek-vm:~# systemctl status ollama.service #确认ollama服务处于运行状态
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2025-02-06 17:13:32 CST; 12min ago
Main PID: 6871 (ollama)
Tasks: 20 (limit: 132577)
Memory: 980.6M
CPU: 8.662s
CGroup: /system.slice/ollama.service
└─6871 /usr/bin/ollama serve
Feb 06 17:20:05 deepseek-vm ollama[6871]: time=2025-02-06T17:20:05.644+08:00 level=INFO sou>
Feb 06 17:23:01 deepseek-vm ollama[6871]: time=2025-02-06T17:23:01.005+08:00 level=INFO sou>
Feb 06 17:24:56 deepseek-vm ollama[6871]: time=2025-02-06T17:24:56.005+08:00 level=INFO sou>
Feb 06 17:25:16 deepseek-vm ollama[6871]: time=2025-02-06T17:25:16.005+08:00 level=INFO sou>
Feb 06 17:25:24 deepseek-vm ollama[6871]: time=2025-02-06T17:25:24.006+08:00 level=INFO sou6、查看日志并确认无报错:
root deepseek-vm:~#journalctl-e-u ollama
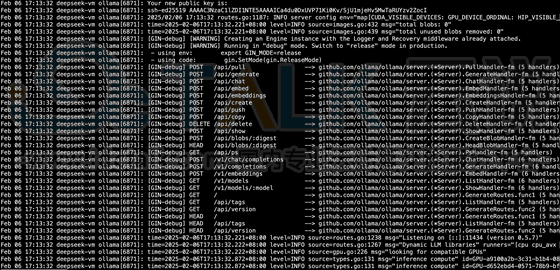
7、验证ollama服务进程和端⼝,11434为ollama的默认监听端⼝:root deepseek-vm:~#netstat-tanlp
三、运行DeepSeek模型
DeepSeek是杭州深度求索公司推出的AI助手,拥有强大的自然语言处理能力,能够理解并回答问题,还能辅助写代码、整理资料和解决复杂的数学问题。
https://ollama.com/search#ollama可以部署不同类型的模型和版本,DeepSeek-R1在很多方面都已经达到或超越OpenAI-o1,具体的模型版本可以根据实际业务需求进行安装,本次为安装deepseek-r1:8b。
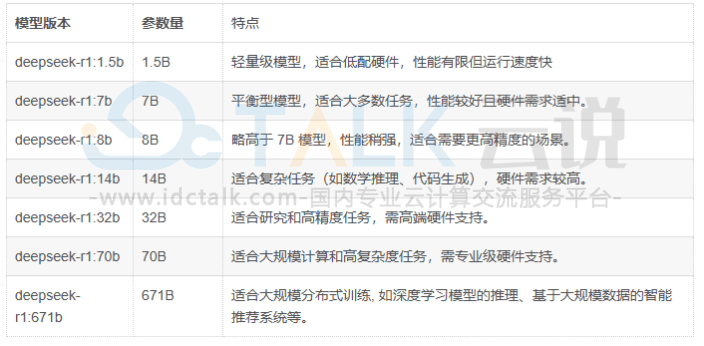
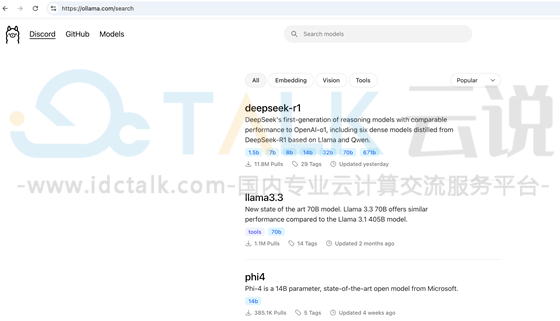
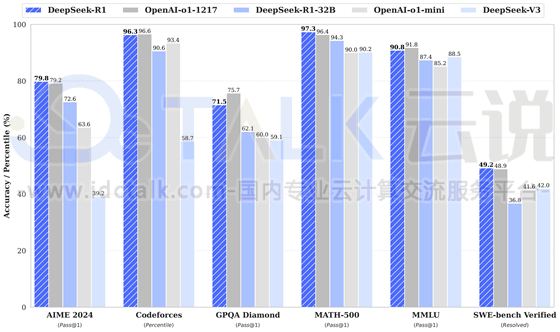
1、运行deepseek-r1:8b:
https://ollama.com/library/deepseek-r1#官⽅⽂档
deepseek-r1:1.5b下载中:
![]()
deepseek-r1:8b下载中:

下载完成后会直接进入命令行交互式窗口,可以通过命令行窗口进行会话。

2、与DeepSeek进行对话。

相关推荐: