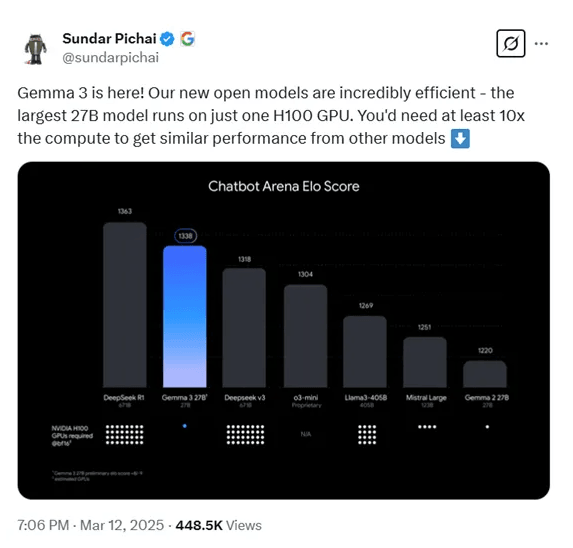
随着DeepSeek的爆火,国内外的人工智能研究机构都压力倍增。近日,谷歌宣布开源最新多模态大模型Gemma-3,主打低成本高性能。Gemma-3共有10亿、40亿、120亿和270亿四种参数。但即便最大的270亿参数,只需要一张H100就能高效推理,同类模型要达到这个效果最少要提升10倍算力,也是目前最强小参数模型。
谷歌表示,Gemma-3是一系列轻量级、最先进的开源模型,其构建基于与Gemini 2.0模型相同的研究和技术。
在LMArena排行榜的初步人类偏好评估中,Gemma-3的表现优于Meta Platforms(META.US)的Llama-405B、DeepSeek-V3和OpenAI的o3-mini。此外,根据盲测LMSYS ChatbotArena数据显示,Gemma-3仅次于DeepSeek的R1-671B,高于OpenAI的o3-mini,Llama3-405B等知名模型。
据谷歌官方博客透露,Gemma-3模型特别为开发者量身打造,旨在助力他们创造出能够跨平台运行的人工智能应用,无论是移动设备还是高性能工作站,都能流畅运行。
在架构设计上,Gemma-3采用了与前两代一样的通用解码器Transformer架构,但进行了众多创新和优化。
为了应对长上下文带来的内存爆炸难题,Gemma-3采用了局部和全局自注意力层交错的架构,每5个局部层之间插入1个全局层,局部层的跨度仅为1024个token。因为只有全局层负责处理长上下文,局部层仅关注1024个token的小跨度,从而降低了内存占用。
为了支持长上下文,Gemma-3模型将上下文长度扩展到了128Ktoken(10亿参数模型为32K)。模型提高了全局自注意力层的RoPE基础频率,从10k提升到1M,而局部层频率保持在10k。同时,采用了类似位置插值的方法来扩展全局自注意力层的跨度,使模型在长上下文场景下能够更好地捕捉信息提升性能。
多模态能力是Gemma-3的一大技术亮点,能够同时处理文本和图像。还集成了定制版的SigLIP视觉编码器,这是一个基于VisionTransformer的编码器,通过CLIP损失的变体进行训练。
为了降低图像处理的推理成本,Gemma-3采用了创新的图像嵌入压缩技术,将视觉嵌入压缩为固定大小的256个向量,从而在不损失关键信息的前提下,显著减少了计算资源的消耗。
此外,Gemma-3还引入了Pan&Scan方法,允许模型灵活处理不同分辨率和宽高比的图像。在实际应用中,Pan&Scan通过将图像分割成多个固定大小的区域,并将这些区域调整到统一的分辨率后输入编码器,从而避免了因图像尺寸不一致而导致的信息丢失或变形问题。这种灵活的图像处理方式不仅提高了模型对图像内容的理解能力,还使其在处理复杂图像场景时表现得更加出色。
为了测试Gemma-3的性能,谷歌在MGSM、Global-MMLU-Lite、WMT24++、RULER、MRCR等众多主流平台进行了评估。
结果显示,Gemma-3在多模态任务中表现出色,例如在DocVQA、InfoVQA和TextVQA等任务中,其性能显著优于前代模型。在长文本处理方面,Gemma-3的27B模型在RULER128K上达到了66.0%的准确率,展现了强大的长文本处理能力。在多语言支持上,Gemma-3在MGSM和Global-MMLU-Lite等任务中也取得了优异成绩。在对话能力评估中,Gemma-3的27B指令调优版本在ChatbotArena中的Elo分数为1338,排名进入前10,接近DeepSeek-R1等大型模型。