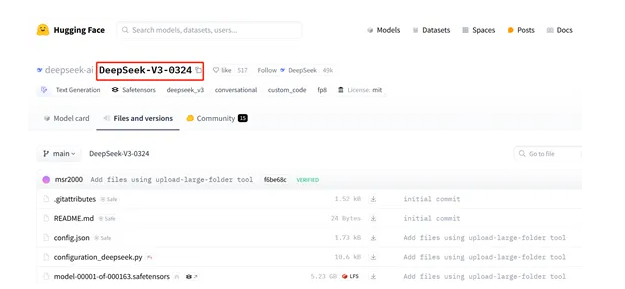
最近,DeepSeek开源了V3模型的最新版本0324。目前V3-0324开源版本目前已经上架开源网站huggingface,模型体积为6850亿参数。深度求索微信官方公众号表示,此次更新属于小版本升级,目前已经在官方网页、App小程序等入口开放。
初代V3模型最为人所熟知的,可能还是“557.6万美金比肩Claude 3.5效果”的超级性价比。而更新后的模型由其新的32KGPU集群上改进的后训练提供支持。
根据国外网友测试显示,V3-0324最大亮点之一就是代码能力,只需要简单的文本提示就能快速开发各种网站、App,可以比肩目前全球最强的闭源代码模型Claude 3.7 Sonnet思维链版本。
为了测试新版V3模型的编程能力,有用户对新版V3与R1下达任务,实际产出的效果已经出现巨大差异。除了对比R1,用户还用类似的提示词,对比了Claude系列。结果显示,当前新版V3在编码能力已经接近claude3.7,同时也是目前第一时间上手中,大家觉得比之前的v3能力提升最大的部分。
除了编程能力,在其他用户的测试中,新版V3在多轮对话中体现出了更强的上下文理解能力。
还有一个让开源社区非常兴奋的事实,新版V3的开源许可与R1一样,也更新变成了MIT开源许可(MIT License),这意味着新版V3有着比初代V3更宽松的开源使用条件。
DeepSeek-V3介绍
DeepSeek-V3是一个拥有6710亿参数的专家混合模型(Moe),其中370亿参数处于激活状态。
为了解决不平衡的专家负载这一难题,DeepSeek对V3进行了大胆创新,提出了辅助损失免费的负载均衡策略,引入“偏差项”。在模型训练过程中,每个专家都被赋予了一个偏差项,它会被添加到相应的亲和力分数上,以此来决定top-K路由。模型会持续监测每一批训练数据中专家的负载情况。如果某个专家负载过重,就像一座桥梁承受了过多的车辆,此时就减小其偏差项;反之,如果负载过轻,就增加偏差项。通过这种动态调整,V3能够在训练过程中有效平衡专家负载,而且相比那些仅依靠纯辅助损失来平衡负载的模型,它的性能得到了显著提升。
此外,V3还采用了节点受限的路由机制,以限制通信成本。在大规模分布式训练中,跨节点的通信开销是一个重要的性能瓶颈。通过确保每个输入最多只能被发送到预设数量的节点上,V3能够显著减少跨节点通信的流量,从而提高训练效率。这种路由机制不仅减少了通信开销,还使得模型能够在保持高效的计算-通信重叠的同时,扩展到更多的节点和专家。