DeepSeek-R1是由杭州深度求索公司推出的一款高性能大模型,具备强大的自然语言处理和深度学习能力。目前很多国内云服务器商都支持部署DeepSeek模型,七牛云就是其中的一家,那么如何高效部署这一模型呢,很多朋友都不太了解。本文就来为大家详细介绍在七牛云GPU云主机上部署DeepSeek-R1模型及最佳实践建议,仅供参考。
一、购买七牛云GPU云主机
七牛云云主机七牛云服务器是一种可弹性伸缩的计算服务,可以帮助用户在短时间内快速启动任意数量的云主机并即时部署应用程序。提供多种机型可选,其中GPU型云主机是Deepseek推荐机型,适用于AI推理、深度学习、图形渲染、科学计算、高性能计算等多种场景。
1、进入七牛云官网,点击“立即注册”,完成注册后登录账号。
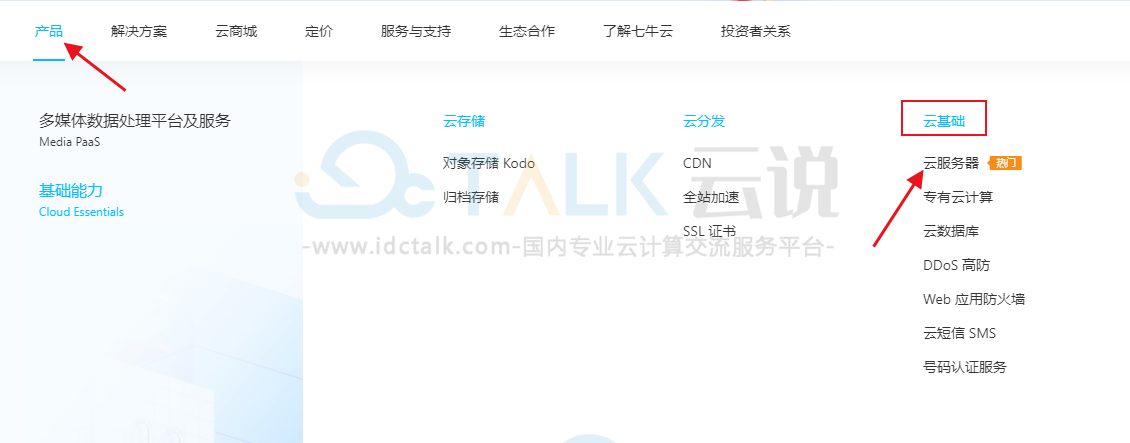
2、点击“产品”,选择“云服务器”。
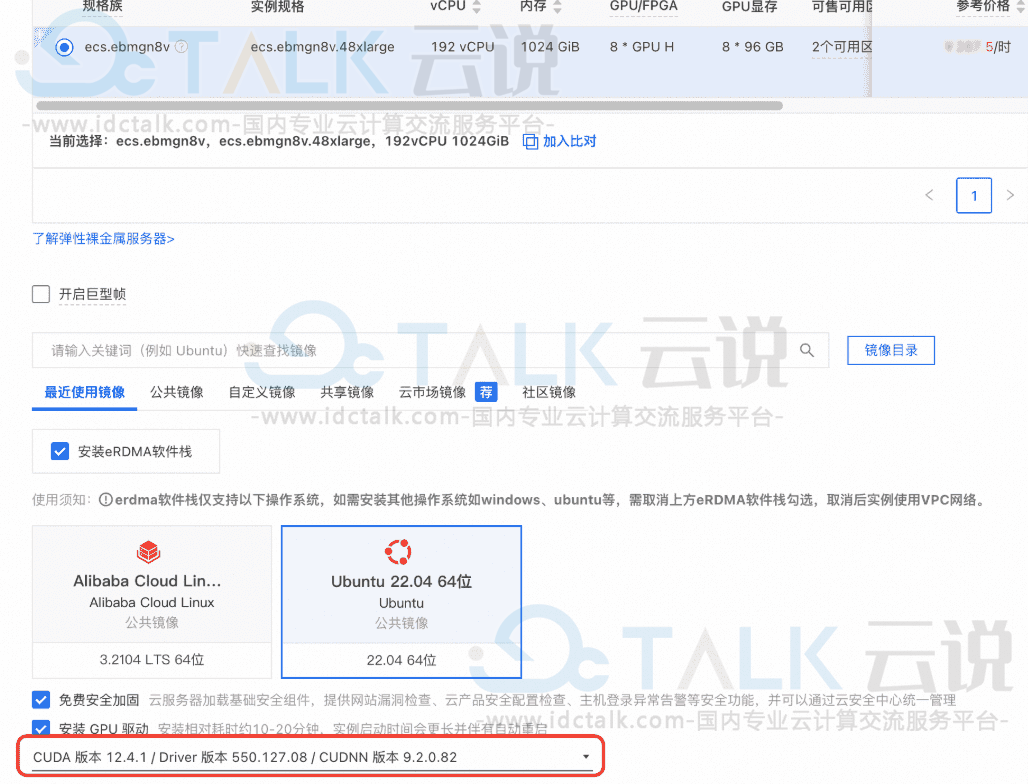
3、在云服务器页面热销产品规格中,选择“GPU型”。用户可以根据下方模型列表选购所需要的云服务器。
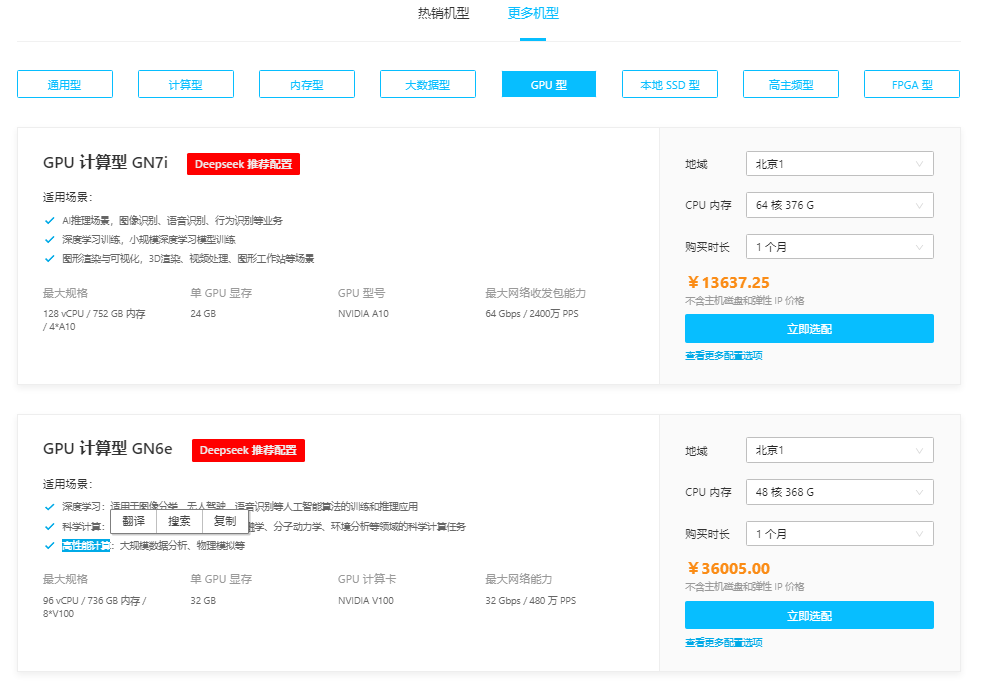
《点击进入官网选购》
目前七牛云官网推出DeepSeek专属GPU主机限时优惠活动,买10个月送2个月。其中P4 GPU云服务器配置为2核8G、单卡显存8GB,每小时仅需1.8元起,适用于部署DeepSeek-R1-Distill-Qwen-7B。
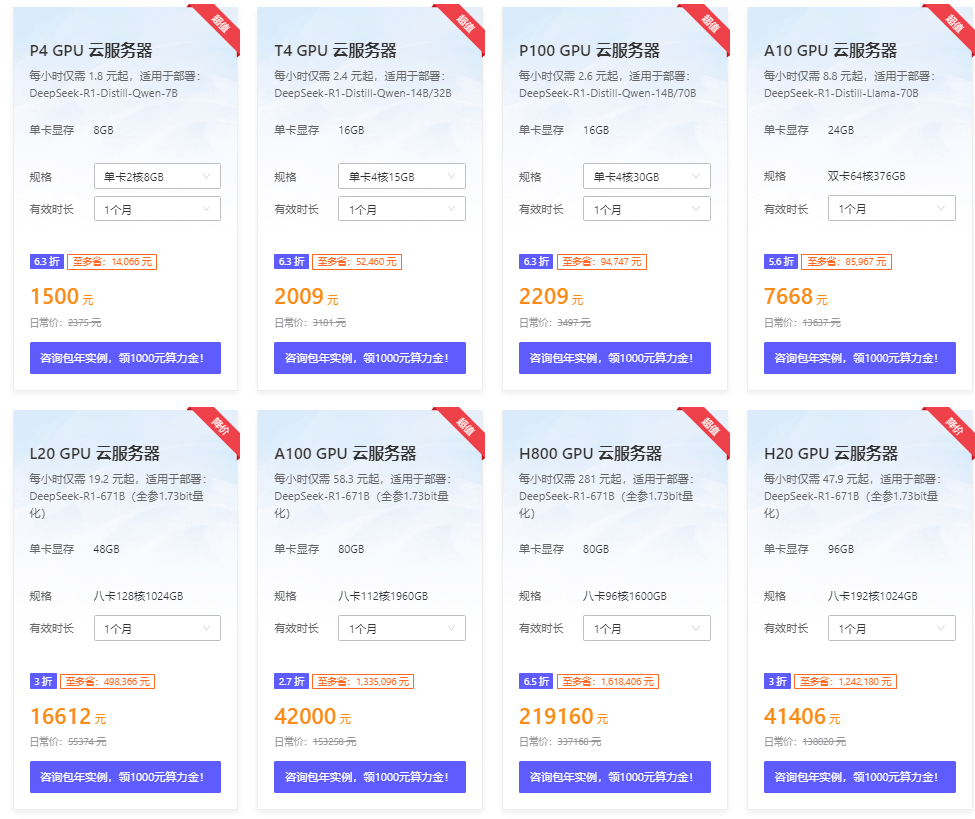
点击进入:七牛云官网
二、部署模型
DeepSeek-R1是一款基于深度学习技术的先进模型,通过大规模强化学习(RL)训练,没有监督微调(SFT)作为初始步骤,在推理方面表现出显著的性能广泛应用于图像识别、自然语言处理等领域。
七牛云提供一键Docker(推荐)、Ollama、VLLM部署,用户可以根据需求部署DeepSeek 7B/8B/14B/32B/70B以及满血671B版本。
1、使用Docker一键部署(推荐)
# 镜像打开后 等待脚本自动下载、配置模型即可
#7B模型
docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek7b_ollama_lite:0.1.0
#8B模型
docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek8b_ollama_lite:0.1.0
#14B模型
docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek14b_ollama_lite:0.1.0
#32B模型
docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek32b_ollama_lite:0.1.0
#70B模型
docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek70b_ollama_lite:0.1.0
2、使用Ollama部署
#STEP 1 安装ollama
curl -fsSL https://ollama.com/install.sh | sh
#STEP 2 运行模型
ollama run deepseek-r1:8b
# 执行命令后自动下载模型(4GB左右)
# 查看ollama日志:
journalctl -u ollama --no-pager
# 或访问本地API
curl -X POST http://127.0.0.1:11434/api/generate -d '{"model":"deepseek-r1:8b", "prompt": "hello"}'
3、使用VLLM部署(多并发需求)
#STEP 1 安装vLLM
pip install vllm
#STEP 2 模型下载
# hfd下载方式:https://hf-mirror.com/
bash hfd.sh deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --local-dir deepseekr1-distill-32B --exclude "*git*" "README.md" "figures" "LICENSE"
#STEP 3 运行vllm服务
cd MODEL/PATH/TO/DEEPSEEK/
vllm serve deepseekr1-distill-32B --tensor-parallel-size 4 --max-model-len 32768 --enforce-eager --api-key deepseek-d-32B
#STEP 4 使用姿势
# http 请求方式
curl http://10.34.52.205:8000/v1/chat/completions \ # http://10.34.52.205:8000: 部署服务的ip地址与端口
-H "Content-Type: application/json" \
-H "Authorization: Bearer deepseek-d-32B" \ # 根据--api-key参数值修改
-d '{
"model": "deepseekr1-distill-32B", # 根据serve 后的 参数值修改
"messages": [
{"role": "system", "content": "You are a helpful assistant."}, # ai扮演的角色
{"role": "user", "content": "Who won the world series in 2020?"} # 提问的问题
]
}'
# python调用方式
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "deepseek-d-32B" # 根据--api-key参数值修改
openai_api_base = "http://10.34.52.205:8000/v1" # 部署服务的ip地址与端口
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="deepseekr1-distill-32B", # 根据--api-key参数值修改
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)
三、DeepSeek-R1满血671B全参数推理模型部署
1、使用Docker一键部署(推荐)
# 镜像打开后 等待脚本自动下载、配置模型即可
docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek_ollama_lite:0.2.0
2、使用Ollama部署
# 1.通过脚本hfd.sh从国内huggingface镜像模下载型
wget https://algorithm.qnaigc.com/DeepSeek/hfd.sh
bash hfd.sh unsloth/DeepSeek-R1-GGUF --include "DeepSeek-R1-UD-IQ1_M" --tool aria2c -x 8
# 2.安装llama.cpp用于模型合并
下载zip压缩包:https://github.com/ggerganov/llama.cpp/archive/refs/heads/master.zip
解压并命名为llama.cpp:mv llama.cpp-master llama.cpp
执行如下指令:
apt-get update
apt-get install build-essential cmake curl libcurl4-openssl-dev -y
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split
cp llama.cpp/build/bin/llama-* llama.cpp
合并模型:./llama.cpp/llama-gguf-split --merge ${PATH-TO-MODEL}/DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_M.gguf
# 3.安装ollama用于模型运行
curl -fsSL https://ollama.com/install.sh | sh
(可能上面因为网络原因会失败,多尝试几次)
# 4.编辑模型描述文件
创建文件:vim DeepSeekQ1_Modelfile
描述文件需要填写模型存放的路径,内容如下;
FROM ${PATH-TO-MODEL}/DeepSeek-R1-UD-IQ1_M.gguf
PARAMETER num_gpu 28
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{{ .Prompt }}<|Assistant|>"
# 5.创建 ollama 模型
ollama会创建一个新模型,且大小与原始模型一样,如果/usr/路径下空间不足,
可以手动指定存储路径:vim /etc/systemd/system/ollama.service
Environment="OLLAMA_MODELS=/disk5/ollama/model"
配置完成后需要重启:
sudo systemctl daemon-reload
sudo systemctl restart ollama
/usr/local/bin/ollama create DeepSeek-R1-UD-IQ1_M -f ${PATH-TO-MODEL}/DeepSeekQ1_Modelfile
# 6.运行模型
ollama run DeepSeek-R1-UD-IQ1_M --verbose
查看ollama日志:journalctl -u ollama --no-pager
# 7.本地API
curl -X POST http://127.0.0.1:11434/api/generate -d '{"model":"DeepSeek-R1-UD-IQ1_M", "prompt": "helllo"}'
四、最佳实践
1、优化模型推理速度
- 使用TensorRT或ONNX Runtime等工具对模型进行加速。
- 使用混合精度推理提升推理速度,七牛云提供的DeepSeek蒸馏模型,采用FP16+FP32混合精度计算,减少显存占用并提高运算效率。
- 优化模型输入输出数据格式,减少数据传输时间。
2、提高模型推理精度
- 使用更高质量的蒸馏数据集训练模型,可参考七牛云DeepSeek r1蒸馏版。
- 调整模型超参数,例如学习率、batch size等。
- 使用数据增强技术提升模型泛化能力。
3、监控模型运行状态
- 使用GPU监控工具(例如nvidia-smi)监控GPU使用率、内存占用等指标。
- 使用日志记录工具记录模型推理过程中的关键信息。
4、确保模型安全性
- 对模型文件进行加密处理,防止模型泄露。
- 对模型输入数据进行合法性校验,防止恶意攻击。
相关推荐:《七牛云基于DeepSeek-R1快速搭建本地专属知识库》