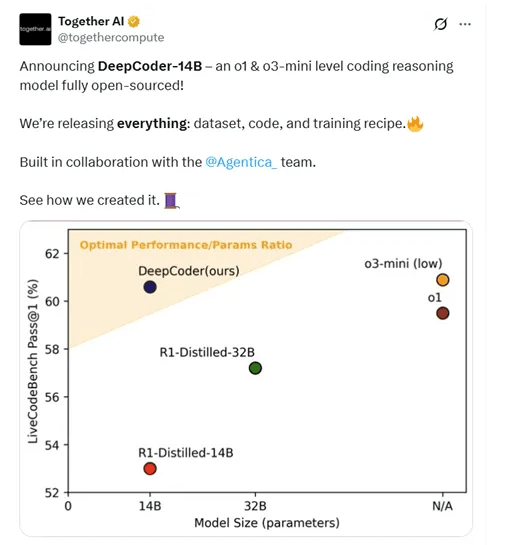
近日,著名大模型训练平台TogetherAI和智能体平台Agentica联合开源了新模型DeepCoder-14B-Preview,引起了广泛关注。该模型以仅有的140亿参数,在代码测试平台LiveCodeBench上的得分为60.6%,超过了OpenAI的o1模型(59.5%),仅略低于o3-mini(60.9%)。这一成绩在Codeforces和AIME2024的评测中也表现出色,与o1和o3-mini不相上下。
Together AI不仅开源了DeepCoder-14B模型权重,还把训练数据集、训练方法、训练日志和优化方法全部公开,极大方便了开发者深入理解模型的开发流程。
DeepCoder是在DeepSeek-R1-Distilled-Qwen-14B基础上,通过分布式强化学习(RL)进行微调而成。为了构建高质量的训练数据集,研究团队收集了24,000个可验证的编程问题,并通过程序验证、测试过滤和去重等步骤确保数据质量。所有问题均通过外部官方解决方案进行验证,并满足严格的单元测试标准。
在代码强化学习训练中,DeepCoder使用了两种沙盒来运行单元测试并计算奖励。Together Code Interpreter是一个快速高效的环境,与RL训练直接兼容,成本低且可扩展性强,能够支持100多个并发沙盒和每分钟1000多个沙盒执行。本地代码沙盒则是一个独立的、受保护的Python子进程,遵循官方LiveCodeBench仓库中的相同评估代码,确保了结果与现有排行榜的一致性。
在奖励函数设计方面,DeepCoder采用了稀疏结果奖励模型(ORM),避免分配部分奖励,从而防止模型通过奖励黑客行为来获取不准确的奖励信号。奖励函数简单而明确:如果生成的代码通过所有采样单元测试,则奖励为1;否则为0。这种设计确保了模型能够专注于生成高质量的代码,而不是通过记忆测试用例来获取奖励。
为了实现更稳定的训练过程,DeepCoder的训练采用了GRPO+,这是对原始GRPO算法的改进版本。通过消除熵损失和KL损失、引入过长过滤和上限裁剪等技术,GRPO+使得模型在训练过程中能够保持稳定的熵值,避免训练崩溃,并且能够更自然地生成较长的输出,从而提高了模型的推理能力。
为了加速端到端的RL训练,DeepCoder团队还开源了优化扩展verl-pipeline,通过一次性流水线技术,使训练、奖励计算和采样的过程完全流水化,大大提高了训练效率。
Together AI致力于提供高性能的AI模型和服务,目前拥有超过3.6万块GB200 NVL72组成的超大GPU算力群。此外Together AI还提供模型微调、Agent智能自动化工作流和合成数据生成等,为大企业提供底层服务。