Llama 2-7B是由Meta研发的开源语言大模型,具有70亿参数规模,适用于对话场景。最新版本的Llama 2现在对个人、创作者、研究人员和企业开放,以便他们可以负责任地进行实验、创新并扩展他们的想法。本文就以阿里云八代实例(g8i/c8i/r8i/hfc8i/hfg8i/hfr8i)为例,来为大家详细介绍下在阿里云服务器上基于xFasterTransformer部署Llama 2-7B模型教程。
本文涉及到的阿里云服务:阿里云第八代Intel CPU实例和xFasterTransformer。
阿里云第八代Intel CPU实例也就是阿里云服务器八代实例,如g8i/c8i/r8i/hfc8i/hfg8i/hfr8i等,采用Intel®Xeon®Emerald Rapids或者Intel®Xeon®Sapphire Rapids,该实例支持使用新的AMX(Advanced Matrix Extensions)指令来加速AI任务。
阿里云服务器是一种安全可靠、弹性可伸缩的云计算服务,可与阿里云各种丰富的云产品无缝衔接,提供丰富的产品规格可选,如经济型、通用算力型、轻量应用、突发性能型、通用型、GPU型等,包括g6、g7、g7a、g8i、c8i、r8i、hfc8i、hfg8i、hfr8i等多种CPU类型,用户可以根据业务需求按需购买。
《点击进入官网选购》
xFasterTransformer是由Intel官方开源的推理框架,为大语言模型(LLM)在CPU X86平台上的部署提供了一种深度优化的解决方案,支持多CPU节点之间的分布式部署方案,使得超大模型在CPU上的部署成为可能。此外,xFasterTransformer提供了C++和Python两种API接口,涵盖了从上层到底层的接口调用,易于用户使用并将xFasterTransformer集成到自有业务框架中。
一、创建阿里云服务器实例
1、进入阿里云官网,点击“注册”,并完成登录操作。
2、点击“产品”,选择“云服务器”>“立即购买”,进入实例购买页面。
3、按照界面提示完成参数配置,创建一台云服务器实例。
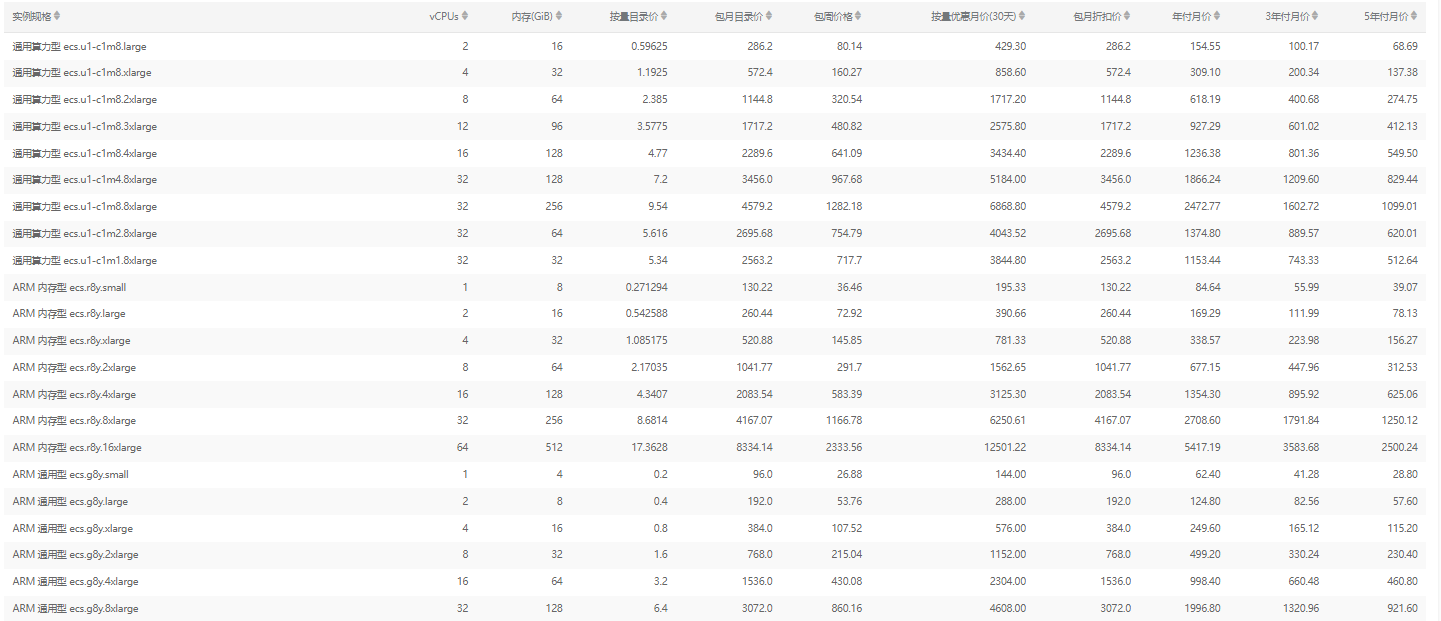
实例:Llama 2-7B运行大概需要16 GiB内存以上,为了保证模型运行的稳定,实例规格至少需要选择ecs.c8i.4xlarge(32 GiB内存)。
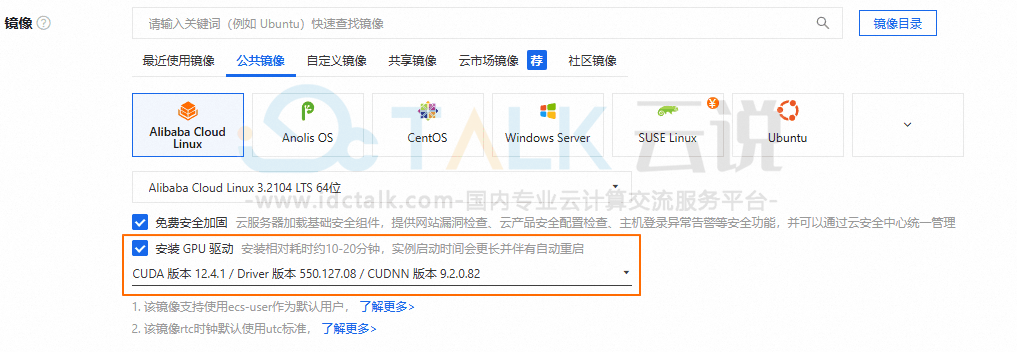
镜像:Alibaba Cloud Linux 3.2104 LTS 64位。
公网IP:选中分配公网IPv4地址,带宽计费模式选择按使用流量,带宽峰值设置为100 Mbps。以加快模型下载速度。

系统盘:Llama 2-7B模型数据下载、转换和运行过程中需要占用60 GiB的存储空间,为了保证模型顺利运行,建议系统盘设置为100 GiB。
4、添加安全组规则。
在阿里云服务器实例安全组的入方向添加安全组规则并放行22端口和8080端口(22端口用于访问SSH服务,8080端口用于请求Llama 2服务)。
二、安装Llama 2-7B模型所需容器环境
Llama是由元宇宙平台公司Meta开源的大型语言模型,它提供了不同规模的模型:
- 2023年7月,Meta公司发布了人工智能模型Llama 2的开源商用版本,包含了70亿、130亿和700亿参数的模型。
- 2024年4月19日,Meta推出了新版本Llama人工智能模型Llama 3,希望与ChatGPT竞争。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k。
- 2025年1月,DeepSeek的出现,让Llama 4在多个Benchmark当中落后。4月5日,Meta发布最新AI大模型Llama 4。
1、远程连接该云服务器实例。
2、安装并启动Docker。
执行以下命令安装Docker社区版本。
#添加Docker软件包源
sudo wget -O /etc/yum.repos.d/docker-ce.repo http://mirrors.cloud.aliyuncs.com/docker-ce/linux/centos/docker-ce.repo
sudo sed -i 's|https://mirrors.aliyun.com|http://mirrors.cloud.aliyuncs.com|g' /etc/yum.repos.d/docker-ce.repo
#Alibaba Cloud Linux3专用的dnf源兼容插件
sudo dnf -y install dnf-plugin-releasever-adapter --repo alinux3-plus
#安装Docker社区版本,容器运行时containerd.io,以及Docker构建和Compose插件
sudo dnf -y install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
#启动Docker
sudo systemctl start docker
#设置Docker守护进程在系统启动时自动启动
sudo systemctl enable docker通过查看Docker版本命令,验证Docker是否安装成功。
sudo docker -v如下图回显信息所示,表示Docker已安装成功。

3、获取并运行Intel xFasterTransformer容器。
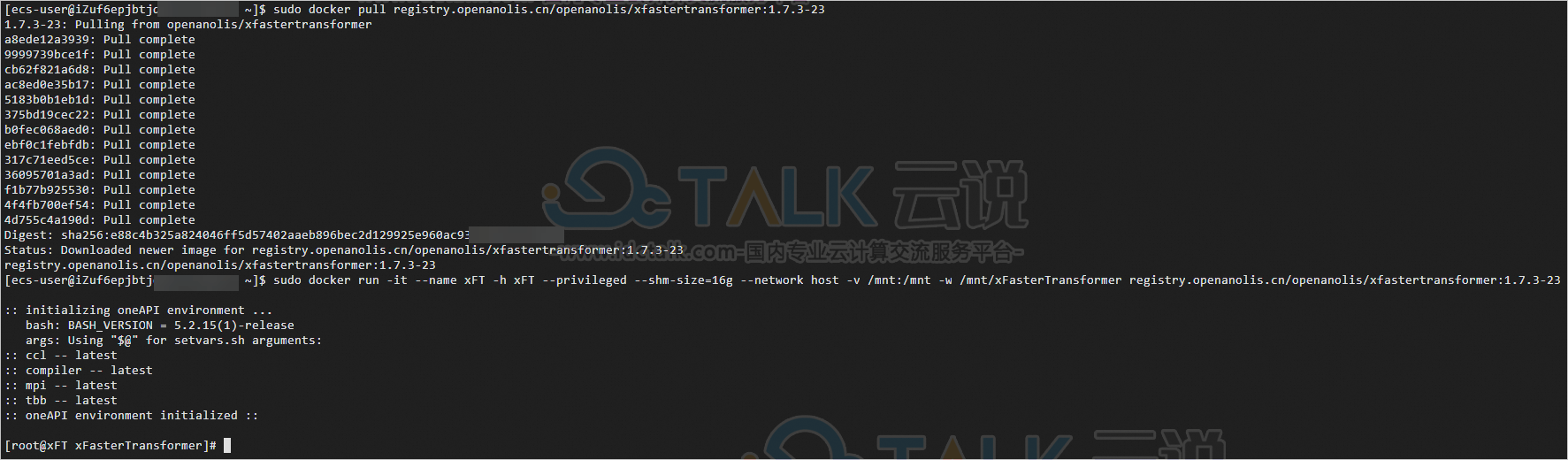
sudo docker pull registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23
sudo docker run -it --name xFT -h xFT --privileged --shm-size=16g --network host -v /mnt:/mnt -w /mnt/xFasterTransformer registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23当出现类似如下信息时,表示已获取并成功运行xFasterTransformer容器。
注:后续操作都需要在容器中运行,如果退出了容器,可以通过以下命令启动并再次进入容器的Shell环境。
sudo docker start xFT
sudo docker exec -it xFT bash4、更新xFasterTransformer脚本代码。
xFasterTransformer镜像中已包含对应版本的脚本代码,可以更新升级到最新的测试脚本。
yum update -y
yum install -y git
cd /root/xFasterTransformer
git pull相关推荐:《阿里云服务器三种远程连接的方法》
三、准备Llama 2-7B模型数据
1、在容器中安装依赖软件。
yum update
yum install -y wget git git-lfs vim tmux2、启用Git LFS。
下载预训练模型需要Git LFS的支持。
git lfs install3、创建并进入模型数据目录。
mkdir /mnt/data
cd /mnt/data4、创建一个tmux session。
tmux5、下载Llama 2-7B预训练模型。
pip install einops transformers_stream_generator tiktoken
git clone https://www.modelscope.cn/modelscope/Llama2-Chinese-7b-Chat-ms.git llama-2-7b6、转换模型数据。
由于下载的模型数据是HuggingFace格式,需要转换成xFasterTransformer格式。生成的模型文件夹为/mnt/data/llama-2-7b-xft。
python -c 'import xfastertransformer as xft; xft.LlamaConvert().convert("/mnt/data/llama-2-7b")'注:不同的模型数据使用的Convert类不同,xFasterTransformer支持以下模型转换类:
- LlamaConvert
- ChatGLMConvert
- ChatGLM2Convert
- ChatGLM3Convert
- OPTConvert
- BaichuanConvert
- QwenConvert
四、运行Llama 2-7B模型
1、安装相关依赖。
pip3 install -i https://mirrors.aliyun.com/pypi/simple/ mlserver2、将/root/xFasterTransformer/serving/mlserver/single-rank/modelsettings.json中模型文件路径修改为正确路径。
sed -i 's/"model_path": "[^"]*"/"model_path": "\/mnt\/data\/llama-2-7b-xft"/' /root/xFasterTransformer/serving/mlserver/single-rank/model-settings.json
sed -i 's/"token_path": "[^"]*"/"token_path": "\/mnt\/data\/llama-2-7b"/' /root/xFasterTransformer/serving/mlserver/single-rank/model-settings.json注:
- 模型其他配置可以在model-settings.json中的parameters:extra中进行配置,包括数据格式,生成长度output_length等。
- MLServer框架支持批处理,将多个请求合并为一个请求进行推理,开启批处理请调整max_batch_size和max_batch_time参数。
- max_batch_size:最多多少个请求可以被合并为一个,当设置N大于1时,最多创建batch size为N的请求。当设置为0或1时禁用该功能。
- max_batch_time:在达到最大批处理大小前,等待新请求的最长时间,单位为秒。当设置为0时,禁用该功能。
3、配置服务IP地址,以启用公网访问。
默认IP地址为127.0.0.1,需要修改为0.0.0.0才能通过公网IP访问服务。配置文件为/root/xFasterTransformer/serving/mlserver/singlerank/settings.json。
sed -i 's/"host": "127\.0\.0\.1"/"host": "0.0.0.0"/g' /root/xFasterTransformer/serving/mlserver/single-rank/settings.json注:默认服务端口为8080,用户也可以修改settings.json中的http_port属性为自定义端口号。
4、运行Llama 2服务。
cd /root/xFasterTransformer/serving/mlserver/single-rank/
OMP_NUM_THREADS=$(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') / 2)) LD_PRELOAD=libiomp5.so numactl -C $(seq -s, 0 2 $(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') - 2))) -m 0 mlserver start .
5、使用curl命令发送服务请求。
Llama 2-7B模型非AI聊天机器人版本,输出结果为续写模式。AI聊天模式请下载Llama 2-chat-7B版本模型,并将输入调整为chat格式:"[INST]{输入Prompt}[/INST]"。
在一台新实例或新的终端上,通过以下命令发送POST请求。请修改其中的ECS公网IP地址。prompt可以修改post_data中的data属性。
post_data='{"inputs": [{"name": "questions", "shape": [1, 1], "datatype": "BYTES", "parameters": {"content_type": "str"}, "data": ["你好,今天过得怎么样?"]}]}'
url="http://<ECS公网IP地址>:8080/v2/models/xft-model/infer"
curl -X POST -H "Content-Type: application/json" -d "$post_data" "$url"6、返回结果如下所示:

相关推荐: