通义千问大模型是由国内云服务器商阿里云自主研发的大模型产品,凭借万亿级超大规模数据训练和领先的算法框架,实现全模态高效精准的模型服务调用。为了让大家更直观地了解通义千问大模型部署教程,本文就以亚马逊云科技为例,为大家介绍一下如何在Amazon EC2实例上构建通义千问大模型,仅供参考。
本文涉及到的亚马逊云科技免费云服务推荐:
1、Amazon EC2
亚马逊云科技现为用户提供的免费云服务器服务,可免费试用12个月,包括每月750个小时的Linux和Windows t2.micro实例。Amazon EC2访问可靠、可扩展、可用性高达99.99%。

2、Amazon Deep Learning AMI
亚马逊云科技Amazon Deep Learning AMI可以为机器学习从业人员和研究人员提供基础设施和各种工具,从而加快在云中进行任意规模的深度学习的速度。无论用户需要Amazon EC2 GPU还是CPU实例,都无需为Deep Learning AMI支付额外费用。

新用户注册亚马逊云科技账户,即可免费使用以上云服务。
活动地址:亚马逊云科技官网
一、创建亚马逊云科技Amazon EC2
1、用户需要注册一个亚马逊云科技账号,并进行登录。
相关推荐:《如何注册亚马逊AWS账号》
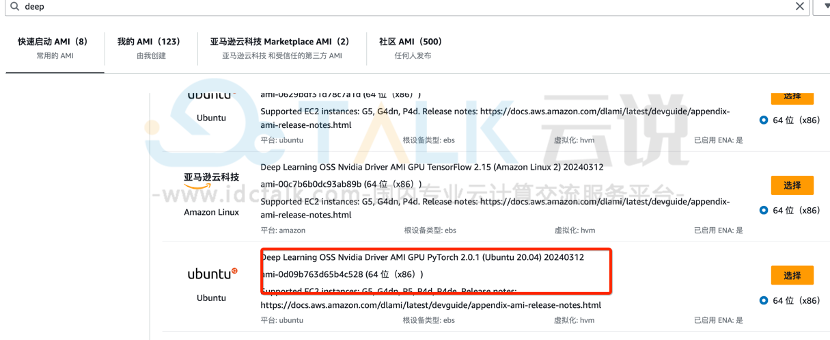
2、进入亚马逊云科技控制台,在页面右上角选择区域,根据服务找到Amazon EC2,在网页左边导航的链接找到AMI,点击进入后,搜索Amazon Deep Learning AMI,选择ubuntu20.04镜像,该镜像已经将英伟达相关驱动安装好。
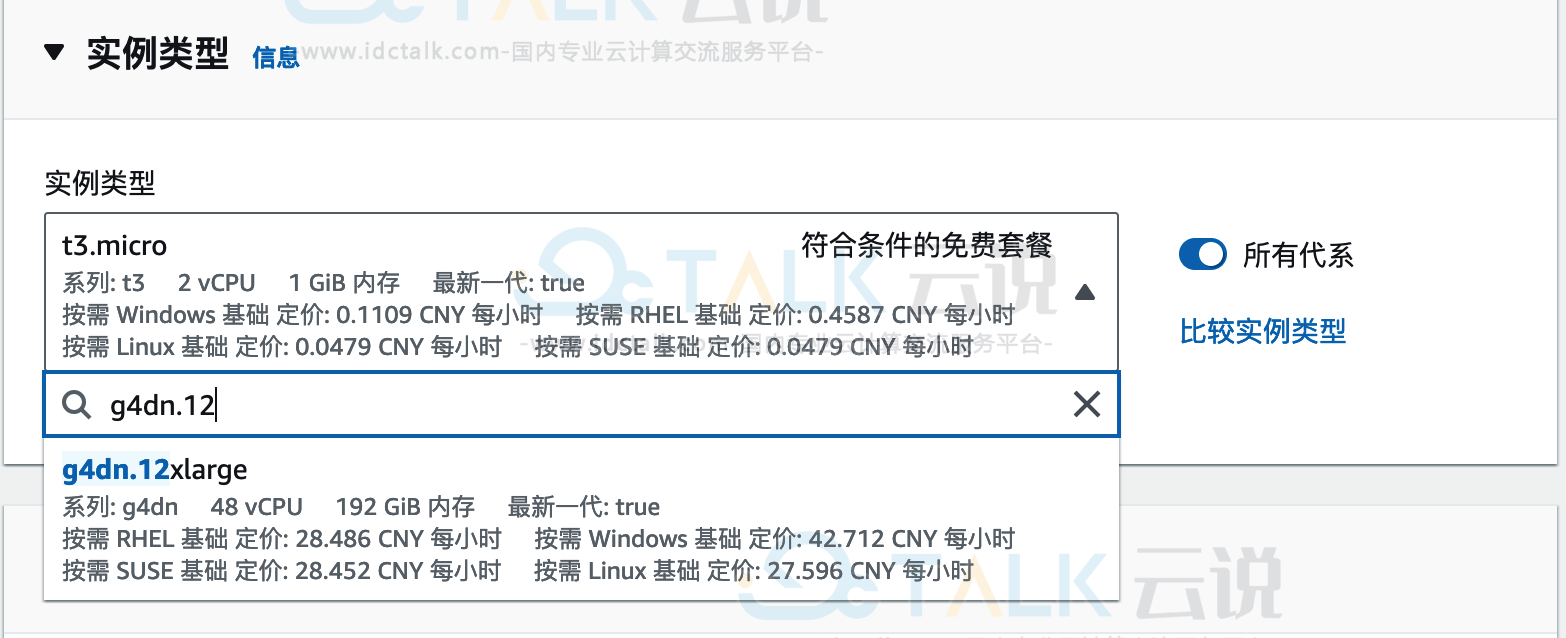
3、选择了AMI后,配置Amazon EC2的实例类型,本文选择g4dn.12xlarge,该实例拥有4颗Tesla T4的卡。实例选择好后,就可以进行配置相应的网络及安全组参数操作,同时开放22端口的访问权限。
4、登录该机器就可以看到,英伟达相应的驱动、CUDA都已经安装好了。如下:
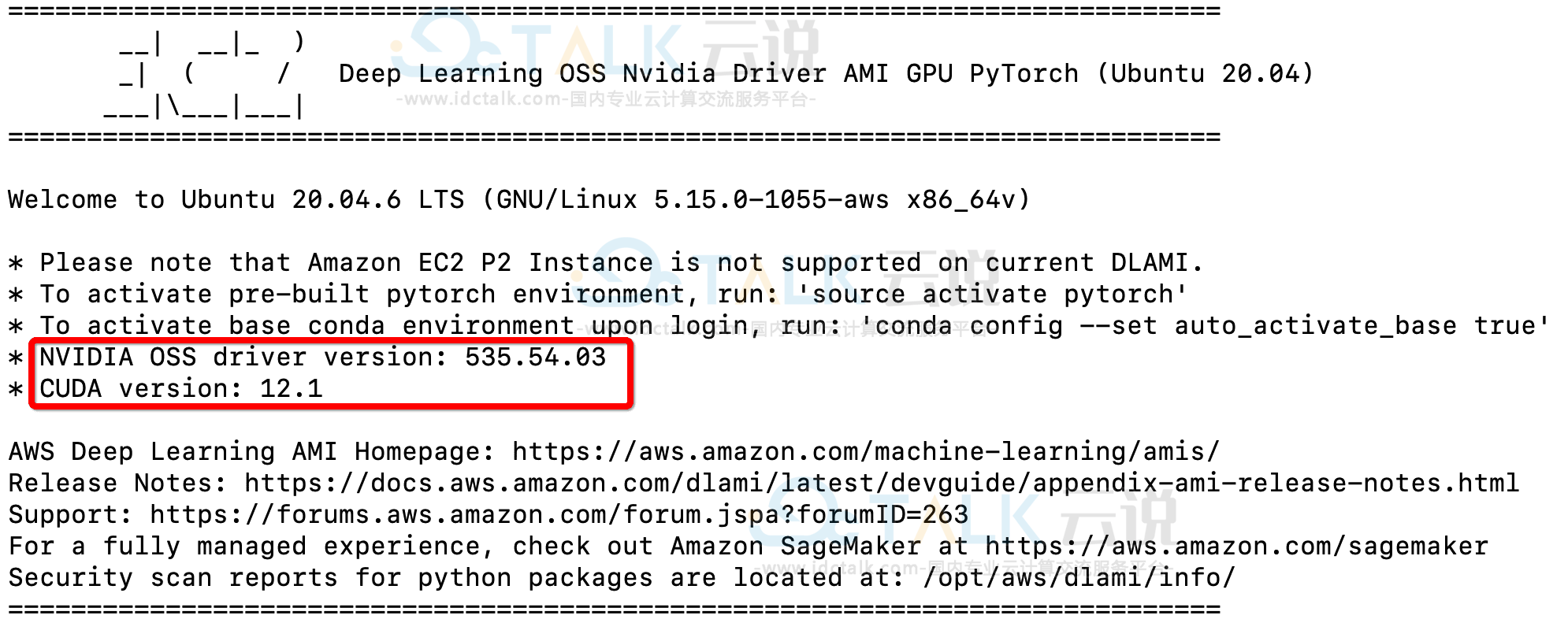
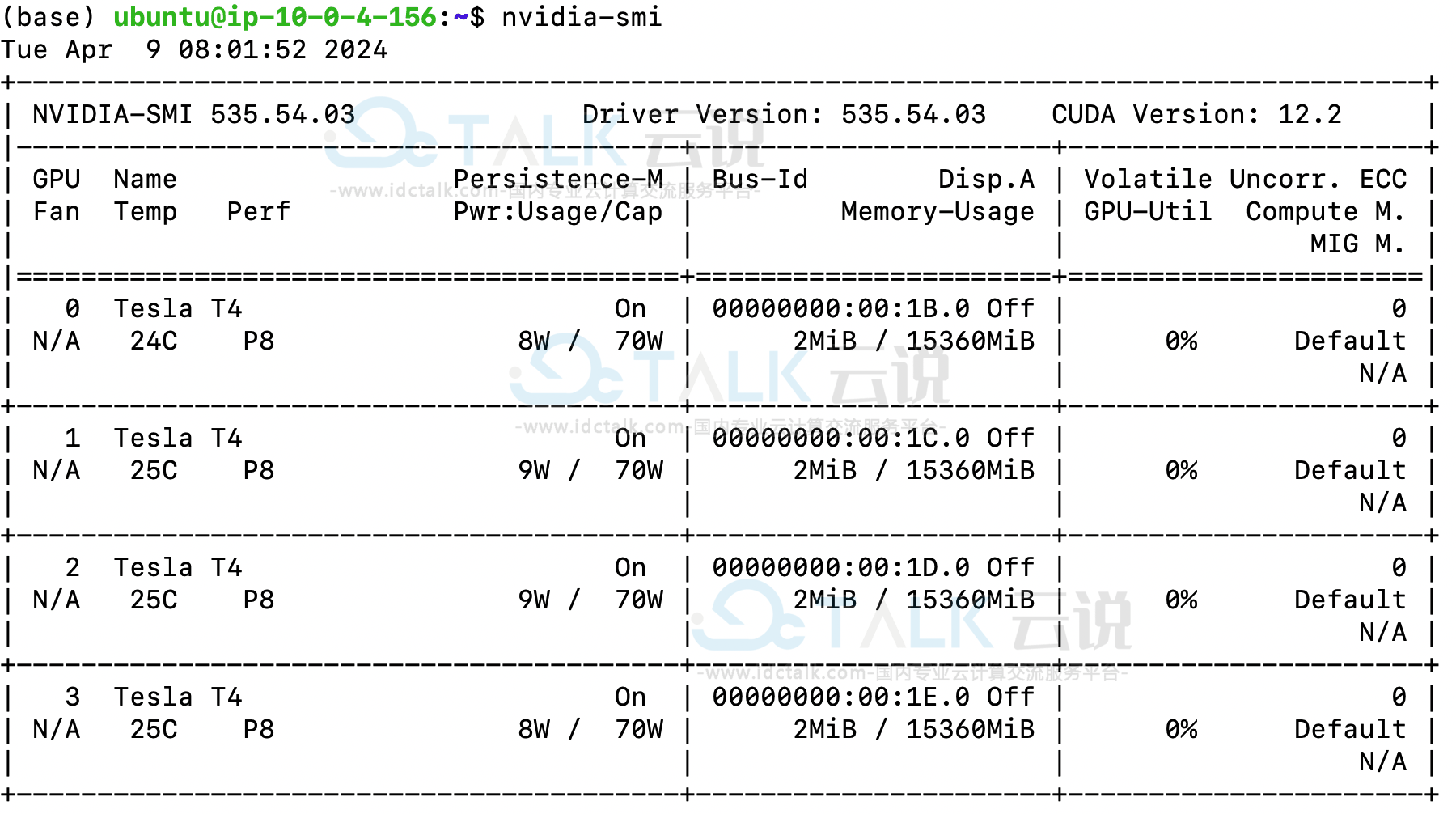
同时用户也可以通过nvidia-smi命令看到该机器的硬件配置。
二、安装并配置Jupyter Notebook
1、利用命令pip install jupyter安装,安装完成后通过命令jupyter notebook--generate-config生成相应的配置文件,如果需要对jupyter notebook设置密码,可以通过jupyter notebook password进行配置。
用户可以对jupyter notebook进行配置,vim~.jupyterjupyter_notebook_config.py,参考配置如下:
c.NotebookApp.ip='*'#允许访问此服务器的IP,星号表示任意IP
c.NotebookApp.open_browser=False#运行时不打开本机浏览器
c.NotebookApp.port=8369#使用的端口,随意设置
c.NotebookApp.enable_mathjax=True#启用MathJax
c.NotebookApp.allow_remote_access=True#允许远程访问
c.NotebookApp.notebook_dir='/home/work/'#设置默认工作目录
2、配置好以后,通过命令nohup jupyter notebook&启动jupyter notebook
3、通过以下下命令打通本地和服务器的隧道:
ssh -i ./.pem -N -f -L 8369:localhost:8369
ubuntu@ec2-.cn-northwest-1.compute.amazonaws.com.cn隧道建立好,本地电脑就可以通过浏览器访问服务器上的jupyter notebook进行代码开发和调试了。
三、下载并部署通义千问大模型
1、登录到服务器,利用git命令下载千问的代码:
git clone https://github.com/QwenLM/Qwen.git2、下载好代码后,进入到Qwen的目录,并利用pip install命令安装相关依赖:
注:需要注意的是因为transformers的版本可能会导致依赖下载失败。本文将master branch中的transformers版本改成了4.32.0,依赖可以正常下载。
3、用户可以在阿里云魔塔社区下载模型文件,本文推荐使用SDK的方式,模型文件默认下载到目录~.cachemodelscopehubqwen下。

用户也可以指定下载位置
#模型下载
from modelscope import snapshot_download
model_dir=snapshot_download('qwen/Qwen-7B-Chat',cache_dir='自己的地址')
4、对模型进行定制时,所需的训练数据格式为JSON数据,具体如下,用户可以提供多条JSON本在一个jsonl文件中。注意每行仅包含一条JSON。
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"用户的问题"},{"role":"assistant","content":"模型的回答"}]}
对于Qwen来讲,它将微调的命令已经准备好了,在finetune这个目录下面。
因为g4dn.12xlarge具有4块卡,用户可以用多卡微调的脚本进行训练。本文以qwen 1.8B chat模型为例进行训练。
命令执行完,可以看到,微调已经开始了,在测试过程中也会发现,多卡比单个GPU的效率高很多。
![]()
5、阿里云通义千问提供了一个叫做openai_api.py来做模型部署,这里使用该脚本进行部署:

部署好以后,用户就可以通过代码进行调用,具体效果如下图所示:

以上,就是在亚马逊云科技Amazon EC2实例上构建通义千问大模型的教程,感兴趣的朋友可以尝试一下。
相关推荐:《亚马逊免费云服务器部署DeepSeek-R1教程》