近日,豆包大模型团队(字节跳动大模型团队)表示,正式发布并开源多模态AI Agent UI-TARS的最新1.5版本。该版本智能体基于视觉-语言框架构建,旨在通过虚拟环境中的任务执行提升基础模型的通用推理能力,在计算机使用、浏览器使用和手机使用等基准测试中均表现非常出色。
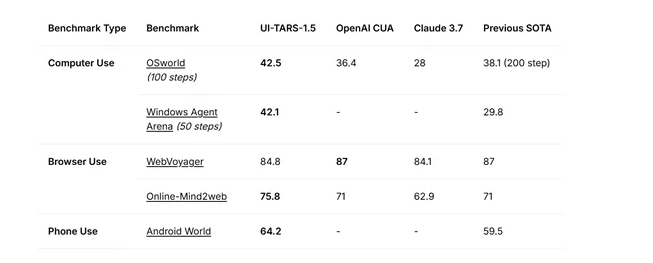
在计算机使用方面,OSworld测试得分为42.5,高于OpenAI CUA的36.4、Claude 3.7的28以及之前的最高水平38.1(200步);Windows Agent Arena(50步)得分为42.1,远超之前的29.8。
在浏览器使用方面,WebVoyager得分为84.8,接近OpenAI CUA和之前最高水平的87,Online-Mind2web得75.8,优于OpenAI CUA的71、Claude 3.7的62.9和之前的71。手机使用方面,Android World得64.2,高于之前的59.5。
在GUI定位方面,UI-TARS-1.5相比之前的最高水平有显著提升,尤其在具有挑战性的ScreenSpotPro基准测试中表现突出。ScreenSpot-V2测试得94.2,高于OpenAI CUA的87.9、Claude 3.7的87.6和之前的91.6;ScreenSpotPro为61.6,远超OpenAI CUA的23.4、Claude 3.7的27.7和之前的43.6。
在推理时间方面,随着推理时间的延长,UI-TARS-1.5呈现出良好的扩展趋势。尽管UI-TARS-1.5并非专为Deep-research任务设计,例如,在互联网上进行多步骤信息搜索研究,但在两个近期具有挑战性的网页浏览基准测试中表现出了强大的通用性。
在SimpleQA测试中,UI-TARS-1.5为83.8,优于GPT-4.5的60,略低于带有搜索功能GPT-4o 90;BrowseComp为2.3,高于GPT4.5的0.6和GPT-4o的1.9。
为评估UI-TARS-1.5的游戏能力,研究人员从poki选取了14款不同的游戏,每个模型在每个游戏中最多允许1000个交互步骤来生成执行轨迹,并进行多次运行。结果显示,UI-TARS-1.5在这些游戏中均取得了100的成绩,而OpenAI CUA和Claude 3.7在部分游戏中得分为0或较低。
UI-TARS-1.5能获得如此出色的性能,“统一的动作建模”是其关键创新之一,将语义上等效的动作标准化,从而实现跨平台的无缝操作和知识迁移。
UI-TARS-1.5在上一代原生GUI智能体基础上,引入强化学习机制优化高阶推理能力,新增“行动前思考”功能,可规划多步骤任务决策。技术层面,团队通过四大维度实现能力升级:增强视觉感知,利用大规模界面截图数据理解元素语义;构建跨平台标准动作空间,提升执行精度;采用System 2推理机制生成任务思维链;建立自动化交互轨迹采集与反思训练范式,使模型持续优化。
相关推荐: