最近,阿里巴巴宣布推出新一代通义千问模型Qwen3并进行开源,该模型是国内首个“混合推理模型”,将“快思考”与“慢思考”集成进同一个模型,参数量仅为DeepSeek-R1的1/3,成本大幅下降,并在ChatBot Arena等榜单中性能全面超越R1、OpenAI-o1等全球顶尖模型,登顶全球最强开源模型。
此次,阿里一共开源了两个MoE模型的权重:Qwen3-235B-A22B和Qwen3-30B-A3B。
Qwen3-235B-A22B:一个拥有2350多亿总参数和220多亿激活参数的大模型。
Qwen3-30B-A3B:一个拥有约300亿总参数和30亿激活参数的小型MoE模型。
此外还开源了6个Dense模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B,均采用Apache 2.0许可。
Qwen3的30B参数MoE模型实现了10倍以上的模型性能杠杆提升,仅激活3B就能媲美上代Qwen2.5-32B模型性能。
Qwen3的稠密模型性能继续突破,一半的参数量可实现同样的高性能,如32B版本的Qwen3模型可跨级超越Qwen2.5-72B性能。
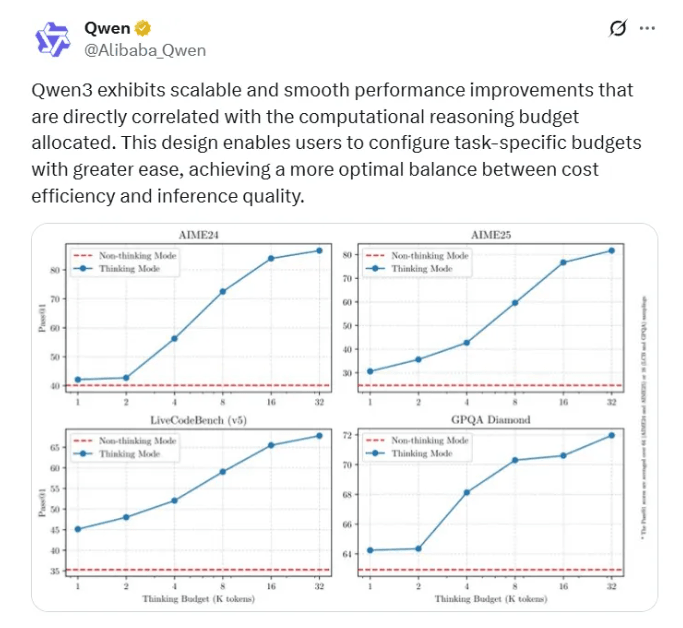
通义千问模型Qwen3的亮点功能是支持两种思考模式:思考模式和非思考模式。思考模式下模型会逐步推理,经深思熟虑后给出最终答案,适合需要深入思考的复杂问题;非思考模式中模型提供快速、近乎即时的响应,适用于对速度要求高于深度的简单问题。
Qwen3除了支持中文之外,还支持葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语等119种语言,覆盖范围非常广。同时阿里还增强了Qwen3模型对Agent和代码能力,支持MCP服务。
在预训练方面,Qwen3的数据集相比Qwen2.5有了显著扩展。Qwen2.5是在18万亿个token上进行预训练的,而Qwen3使用的数据量几乎是其两倍,达到了约36万亿个token,涵盖了119种语言和方言。
目前,用户可在魔搭社区、HuggingFace等平台下载模型并商用,也可以通过阿里云百炼调用千问3的API服务。个人用户可通过通义APP体验千问3。