








































概览
产品介绍
IMagen是Google AI研发的一款文字到图像生成模型,可以生成非常逼真和细致的图像,甚至可以达到照片级别的质量。IMagen可以很好地理解输入文本的含义和细节,并且能够根据文本生成与之一致和对齐的图像。IMagen不需要在特定领域或数据集上进行训练,它只需要一个通用的语言模型和一个通用的图像生成模型。这意味着IMagen可以应对各种各样的文本输入,甚至是一些很奇怪或很难想象的场景。IMagen可以用于创意设计、艺术创作、教育、娱乐、科学和工程等应用场景。
产品功能介绍
图像生成
用户只需输入简单的文字描述,Imagen便能根据这些描述生成符合要求的图片。这一功能在设计、广告、媒体等领域具有广泛的应用价值。
条件图像生成与编辑
用户可以在已有的图片基础上,通过设定特定的条件来进行局部或整体的编辑。
隐式图像合成
隐式图像合成是Imagen一项极具创意和潜力的功能,隐式图像合成允许用户在不直接操作图像的情况下,通过组合多个描述或条件来生成全新的图像。这种合成方式打破了传统图像编辑的局限,为用户提供了更为广阔和自由的创作空间。
-

谷歌推出全新图像生成器Imagen 3
最近谷歌宣布推出了Imagen 3,进一步增强了文本生成图片的技术能力。Imagen 3在文本语义还原、色彩搭配、文本嵌入、图像细节、光影效果等方面都比Imagen 2有了大幅度的提升。目前Imagen 3已经可以在美国地区使用,未来谷歌会持续扩大使用范围。 传统的扩散模型在处理高维复杂数据、图像质量和多样性以及训练稳定性方面有一些缺点,同时开发成本也比较高。在这种背景下谷歌推出了使用了潜空间扩散模型的Imagen 3。 潜空间是指一个被压缩的表示形式,模型可以在这个表示形式中进行操作,而不是直接在原始图像像素上进 -

IMagen是什么? IMagen什么意思
IMagen是什么?IMagen是Google AI研发的一款文字到图像生成模型,可以生成非常逼真和细致的图像,甚至可以达到照片级别的质量。IMagen可以很好地理解输入文本的含义和细节,并且能够根据文本生成与之一致和对齐的图像,可以应用于创意设计、艺术创作、教育、娱乐、科学和工程等场景。 Imagen模型中包含一个frozen T5-XXL编码器和一个 64×64 的图像扩散模型中,并带有两个超分辨率扩散模型,用于生成 256×256 和 1024×1024 的图像。 其中,所有扩散模型都以文本嵌入序列为条件,并 -

苹果开源最新通用多模态视觉模型AIMv2
苹果的研究人员最近开源了最新通用多模态视觉模型AIMv2,它是一系列开放式视觉编码器,包含19个不同参数大小的模型——从300M到2.7B,支持224、336和448像素的分辨率,适用于手机、PC等不同类型的设备。 AIMV2使用了一种创新的多模态自回归预训练方法,将视觉与文本信息深度融合,为视觉模型领域带来了新的技术突破。简而言之,就是AIMV2不再局限于仅处理视觉信息的传统模式,而是将图像和文本整合为统一的序列进行预训练。 在这个过程中,图像被划分为一系列不重叠的Patches,形成图像token序列。文本则被 -
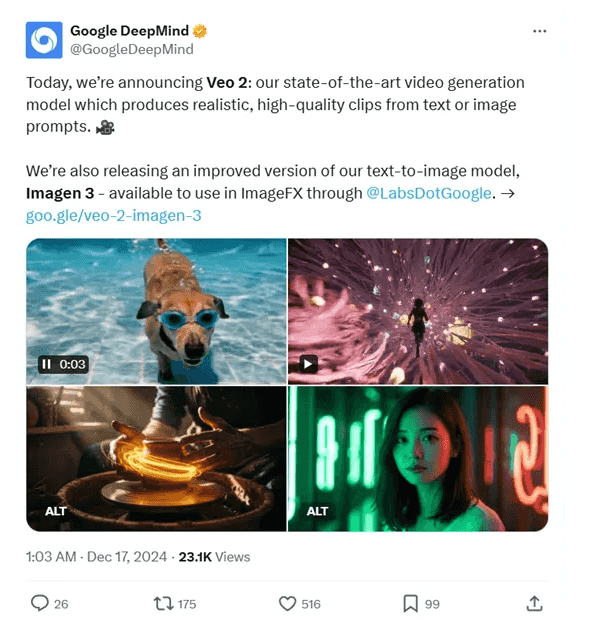
谷歌推出最新视频生成模型Veo 2
近日,谷歌Deepmind推出了最新文生视频模型Veo 2,可直接生成8秒4K视频,同时能根据用户对镜头类型、拍摄角度、电影效果等需求进行精准摄像头生成,包括低角度跟踪镜头、特写镜头等不同类型。 值得一提的是,Veo 2具备很强的物理模拟效果,在动作一致性、光影处理、运动频率以及写真等方面非常优秀。 Veo2作为谷歌的新一代视频生成工具,能够生成多样化主题和风格的高质量视频。谷歌在发布会上指出,这一模型在真实感和细节捕捉方面表现出色,特别是在模拟人类表情和电影效果方面,其技术水平已经达到行业前沿。Veo2不仅支持自 -
OpenAI发布全新扩散模型sCM
近日OpenAI发布了全新扩散模型方法sCM,仅需两步即可生成高质量图片、3D模型等,速度提升约50倍。该模型以简化的连续时间一致性模型为基础,提供更高的训练稳定性和可扩展性。 sCM扩散模型核心原理是基于一致性模型思路,通过直接将噪声转换为无噪声样本来生成数据。与传统扩散模型不同,一致性模型可找到一条更直接的路径,在单步或少数几步内直接从噪声状态跳跃到数据状态。 sCM扩散模型的特点 1、采用连续时间框架 sCM采用了连续时间框架,使得模型在理论上可以在连续的时间轴上进行操作,从而避免了离散时间模型中的离散化误差 -
谷歌产品大更新:Bard可生成图像;文生音乐平台等5大免费功能
2月2日,谷歌在官网对生成式AI产品进行了大更新,包括类ChatGPT聊天助手Bard可以通过文本提示生成图像; 全新的文生音乐平台MusicFX;新的文生图像平台ImageFX;新的文本扩写平台TextFX;在谷歌地图中增加生成式AI功能,用文本提示快速查找路线、店铺等。 值得一提的是,这5大功能目前都是免费使用。其中,文生图像平台ImageFX的功能非常强悍,支持对文本提示中的“关键元素”进行可视化控制。 目前,无论是Midjourney还是DALL·E 3都无法做到(二者无法可视化控制,只能用文本),这对于生
-
谷歌推出全新图像生成器Imagen 3
最近谷歌宣布推出了Imagen 3,进一步增强了文本生成图片的技术能力。Imagen 3在文本语义还原、色彩搭配、文本嵌入、图像细节、光影效果等方面都比Imagen 2有了大幅度的提升。目前Imagen 3已经可以在美国地区使用,未来谷歌会持续扩大使用范围。 传统的扩散模型在处理高维复杂数据、图像质量和多样性以及训练稳定性方面有一些缺点,同时开发成本也比较高。在这种背景下谷歌推出了使用了潜空间扩散模型的Imagen 3。 潜空间是指一个被压缩的表示形式,模型可以在这个表示形式中进行操作,而不是直接在原始图像像素上进 -
苹果开源最新通用多模态视觉模型AIMv2
苹果的研究人员最近开源了最新通用多模态视觉模型AIMv2,它是一系列开放式视觉编码器,包含19个不同参数大小的模型——从300M到2.7B,支持224、336和448像素的分辨率,适用于手机、PC等不同类型的设备。 AIMV2使用了一种创新的多模态自回归预训练方法,将视觉与文本信息深度融合,为视觉模型领域带来了新的技术突破。简而言之,就是AIMV2不再局限于仅处理视觉信息的传统模式,而是将图像和文本整合为统一的序列进行预训练。 在这个过程中,图像被划分为一系列不重叠的Patches,形成图像token序列。文本则被 -
谷歌推出最新视频生成模型Veo 2
近日,谷歌Deepmind推出了最新文生视频模型Veo 2,可直接生成8秒4K视频,同时能根据用户对镜头类型、拍摄角度、电影效果等需求进行精准摄像头生成,包括低角度跟踪镜头、特写镜头等不同类型。 值得一提的是,Veo 2具备很强的物理模拟效果,在动作一致性、光影处理、运动频率以及写真等方面非常优秀。 Veo2作为谷歌的新一代视频生成工具,能够生成多样化主题和风格的高质量视频。谷歌在发布会上指出,这一模型在真实感和细节捕捉方面表现出色,特别是在模拟人类表情和电影效果方面,其技术水平已经达到行业前沿。Veo2不仅支持自 -
OpenAI发布全新扩散模型sCM
近日OpenAI发布了全新扩散模型方法sCM,仅需两步即可生成高质量图片、3D模型等,速度提升约50倍。该模型以简化的连续时间一致性模型为基础,提供更高的训练稳定性和可扩展性。 sCM扩散模型核心原理是基于一致性模型思路,通过直接将噪声转换为无噪声样本来生成数据。与传统扩散模型不同,一致性模型可找到一条更直接的路径,在单步或少数几步内直接从噪声状态跳跃到数据状态。 sCM扩散模型的特点 1、采用连续时间框架 sCM采用了连续时间框架,使得模型在理论上可以在连续的时间轴上进行操作,从而避免了离散时间模型中的离散化误差 -
谷歌产品大更新:Bard可生成图像;文生音乐平台等5大免费功能
2月2日,谷歌在官网对生成式AI产品进行了大更新,包括类ChatGPT聊天助手Bard可以通过文本提示生成图像; 全新的文生音乐平台MusicFX;新的文生图像平台ImageFX;新的文本扩写平台TextFX;在谷歌地图中增加生成式AI功能,用文本提示快速查找路线、店铺等。 值得一提的是,这5大功能目前都是免费使用。其中,文生图像平台ImageFX的功能非常强悍,支持对文本提示中的“关键元素”进行可视化控制。 目前,无论是Midjourney还是DALL·E 3都无法做到(二者无法可视化控制,只能用文本),这对于生 -

谷歌对Vertex AI大更新 支持Llama 2模型微调
8月30日,谷歌在美国旧金山召开“Google Cloud Next 23”,生成式AI成为本次大会的核心主题。谷歌围绕生成式AI,从基础设施、开发工具到产品全方位多维度地进行了重磅更新。此外,谷歌为了帮助全球开发者提升对生成式AI、大语言模型等开发效率,加速应用场景化落地,对Vertex AI进行了多项功能优化,尤其是发布了全球首个数字水印,用于AI生成的图像识别和安全。 Vertex AI是Google Cloud发布的一款机器学习开发平台,可提供整个模型开发生命周期管理,包括数据预处理、模型训练、模型库选择、
-
IMagen是什么? IMagen什么意思
IMagen是什么?IMagen是Google AI研发的一款文字到图像生成模型,可以生成非常逼真和细致的图像,甚至可以达到照片级别的质量。IMagen可以很好地理解输入文本的含义和细节,并且能够根据文本生成与之一致和对齐的图像,可以应用于创意设计、艺术创作、教育、娱乐、科学和工程等场景。 Imagen模型中包含一个frozen T5-XXL编码器和一个 64×64 的图像扩散模型中,并带有两个超分辨率扩散模型,用于生成 256×256 和 1024×1024 的图像。 其中,所有扩散模型都以文本嵌入序列为条件,并
