概览
产品介绍
Llama 3是Meta公司发布的大型语言模型,于当地时间2024年4月18日对外公布。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k。与Llama-2相比,Llama-3使用了15T tokens的训练数据,在推理、数学、代码生成、指令跟踪等能力获得大幅度提升。此外,Llama-3还使用了分组查询注意力、掩码等创新技术,帮助开发者以最低的能耗获取绝佳的性能。Llama 3在多种行业基准测试上展现了先进的性能,并提供了包括改进的推理能力在内的新功能。
产品特点介绍
参数规模
Llama 3提供了8B和70B两种参数规模的模型,相比Llama 2参数数量的增加使得植型能够捕捉和学习更复杂的语言槿式
训练数据集
Llama 3的训练数据集比Llama 2大了7倍,包含了超过15万亿个token,其中包括4倍的代码数据,这使得Llama 3在理解和生成代码方面更加出色。
模型架构
Llama 3采用了更高效的分词器和分组查询注意力技术,提高了模型的推理效率和处理长文本的能力。
性能提升
通过改进的预训练和后训练过程,Llama 3在减少错误拒绝率、提升响应对齐和增加模型响应多样性方面取得了进步
安全性
引入了Lama Guard 2等新的信任和安全工具,以及Code shield和CyberSec Eval 2,增强了模型的安全性和可靠性。
多语言支持
Llama 3在预训练数据中加入了超过30种语言的高质量非英语数据,为未来的多语言能力打下了基础。
推理和代码生成
Llama 3在推理、代码生成和指令跟随等方面展现了大幅提升的能力,使其在复杂任务处理上更加精准和高效。
-

Meta开源多模态模型Llama 3.2
最近,Meta开源了多模态模型Llama 3.2,此次开源的是1B和3B轻量级模型。Meta使用了带有LoRA适配器的量化感知训练和SpinQuant进行了大幅度性能优化,平均减少了41%的内存使用、减少56%的模型规模,但推理效率却提升了2—4倍。 作为整个系列里最轻量级的模型,Llama3.2 1B和3B适合边缘设备和移动应用程序的检索和摘要,可用于个人信息管理和多语言知识检索等,支持128k标记的上下文长度,可在手机、平板电脑等设备中使用。 Llama3.2 1B和3B特点介绍: 1、采用标准的Transfo -

Meta发布多模态Llama 3.2新模型
最近Meta发布了多模态Llama 3.2新模型,能够同时理解图像和文本。此次一共发布了四个版本,分别为Llama 3.2 1B、Llama 3.2 3B、Llama 3.2 90B和Llama 3.2 11B。 其中Llama 3.2 1B和Llama 3.2 3B是整个系列最轻量级的模型,适合边缘设备和移动应用程序的检索和摘要,可用于个人信息管理和多语言知识检索等,支持128k标记的上下文长度,可在手机、平板电脑等设备中使用。而Llama 3.2 90B和Llama 3.2 11B则是Llama首次发布的多模态 -
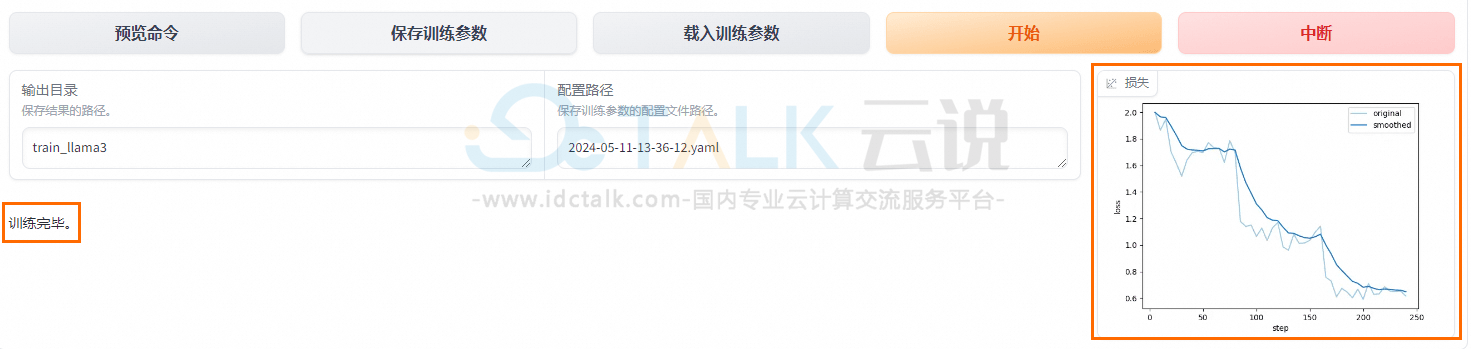
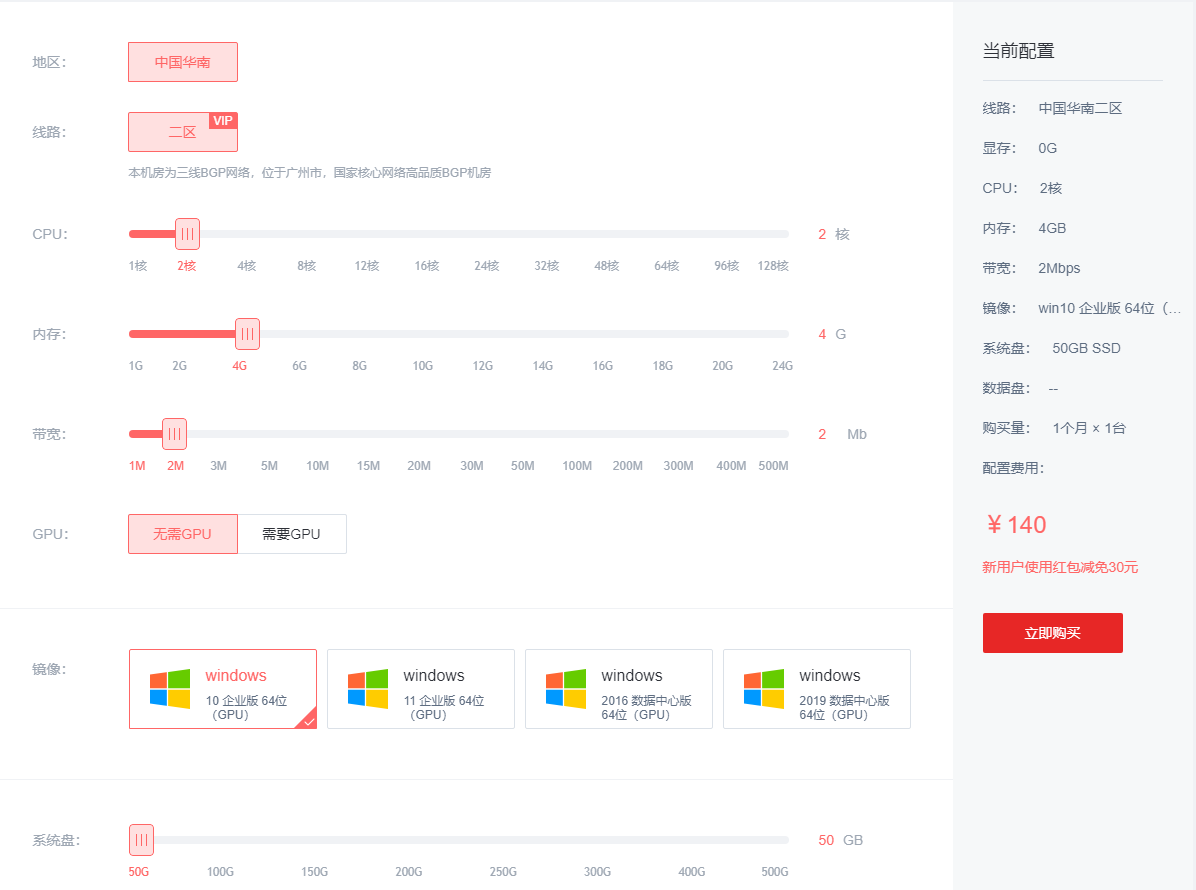
阿里云PAI使用LLaMA Factory微调LlaMA 3模型的教程
LLaMA Factory是什么?LLaMA Factory是一个开源微调框架,旨在简化和优化大规模语言模型的训练和部署。LLaMA Factory集成了业界广泛使用的微调技术,支持通过Web UI界面零代码微调大模型。本文将基于LlaMA 3模型,为大家介绍阿里云PAI使用LLaMA Factory微调LlaMA 3模型的具体操作方法。 点击进入:阿里云官网 前提条件: 1、创建工作空间。 2、创建DSW实例,其中关键参数配置如下: 实例规格选择:建议使用24 GB显存的A10(ecs.gn7i-c8g1.2xl -

Meta发布首个超GPT-4o开源大模型Llama 3.1
最近,Meta宣布推出迄今为止最强大的开源模型——Llama 3.1。Llama 3.1共有8B、70B及405B三种版本,其中405B版本是目前最大的开源模型之一。 Llama 3.1 405B版本在多项测试中一举超越GPT-4o和Claude 3.5 Sonnet,支持128K上下文长度,英语、法语、德语等8种语言,能生成代码、文本、文本摘要等。 Llama 3.1 405B版本现在没有开放还在继续开发中。 Meta更改了开源许可证,这就意味着开发者是可以使用Llama 3.1系列模型的输出去优化其他模型的。这 -

Meta发布了最新大模型Llama 3
随着人工智能大战持续升级,4月19日,全球科技、社交巨头Meta在官网,正式发布了开源大模型——Llama 3。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k。 Meta表示,通过使用更高质量的训练数据和指令微调,Llama 3比前代Llama 2有了“显著提升”。Llama 3使用了15T tokens的训练数据,在推理、数学、代码生成、指令跟踪等能力获得大幅度提升。此外,Llama 3还使用了分组查询注意力、掩码等创新技术,帮助开发者以最低的能耗获取绝佳的性能。 -
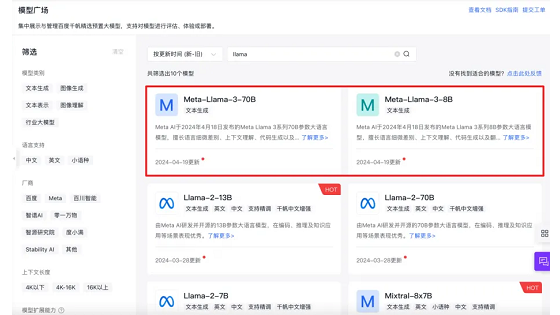
百度智能云:国内首家推出针对Llama3全系列训练方案
4月18日,Facebook母公司Meta重磅推出了号称“史上最强大开源模型”的Llama3。4月19日,百度智能云千帆大模型成为国内首家推出针对Llama3全系列版本的训练推理方案的平台。现已开放邀约测试。 百度智能云千帆大模型平台中各种尺寸模型定制工具千帆ModelBuilder已上架最新Llama 3系列模型,用户在「体验中心」可以随时体验模型效果。同时,开发者可以根据需求上传数据,在千帆ModelBuilder上对部分模型进行精调SFT,提升模型效果,打造您的个人专属模型。 千帆ModelBuilder作为
-
Meta开源多模态模型Llama 3.2
最近,Meta开源了多模态模型Llama 3.2,此次开源的是1B和3B轻量级模型。Meta使用了带有LoRA适配器的量化感知训练和SpinQuant进行了大幅度性能优化,平均减少了41%的内存使用、减少56%的模型规模,但推理效率却提升了2—4倍。 作为整个系列里最轻量级的模型,Llama3.2 1B和3B适合边缘设备和移动应用程序的检索和摘要,可用于个人信息管理和多语言知识检索等,支持128k标记的上下文长度,可在手机、平板电脑等设备中使用。 Llama3.2 1B和3B特点介绍: 1、采用标准的Transfo -
Meta发布多模态Llama 3.2新模型
最近Meta发布了多模态Llama 3.2新模型,能够同时理解图像和文本。此次一共发布了四个版本,分别为Llama 3.2 1B、Llama 3.2 3B、Llama 3.2 90B和Llama 3.2 11B。 其中Llama 3.2 1B和Llama 3.2 3B是整个系列最轻量级的模型,适合边缘设备和移动应用程序的检索和摘要,可用于个人信息管理和多语言知识检索等,支持128k标记的上下文长度,可在手机、平板电脑等设备中使用。而Llama 3.2 90B和Llama 3.2 11B则是Llama首次发布的多模态 -
Meta发布首个超GPT-4o开源大模型Llama 3.1
最近,Meta宣布推出迄今为止最强大的开源模型——Llama 3.1。Llama 3.1共有8B、70B及405B三种版本,其中405B版本是目前最大的开源模型之一。 Llama 3.1 405B版本在多项测试中一举超越GPT-4o和Claude 3.5 Sonnet,支持128K上下文长度,英语、法语、德语等8种语言,能生成代码、文本、文本摘要等。 Llama 3.1 405B版本现在没有开放还在继续开发中。 Meta更改了开源许可证,这就意味着开发者是可以使用Llama 3.1系列模型的输出去优化其他模型的。这 -
Meta发布了最新大模型Llama 3
随着人工智能大战持续升级,4月19日,全球科技、社交巨头Meta在官网,正式发布了开源大模型——Llama 3。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,上下文窗口为8k。 Meta表示,通过使用更高质量的训练数据和指令微调,Llama 3比前代Llama 2有了“显著提升”。Llama 3使用了15T tokens的训练数据,在推理、数学、代码生成、指令跟踪等能力获得大幅度提升。此外,Llama 3还使用了分组查询注意力、掩码等创新技术,帮助开发者以最低的能耗获取绝佳的性能。 -
百度智能云:国内首家推出针对Llama3全系列训练方案
4月18日,Facebook母公司Meta重磅推出了号称“史上最强大开源模型”的Llama3。4月19日,百度智能云千帆大模型成为国内首家推出针对Llama3全系列版本的训练推理方案的平台。现已开放邀约测试。 百度智能云千帆大模型平台中各种尺寸模型定制工具千帆ModelBuilder已上架最新Llama 3系列模型,用户在「体验中心」可以随时体验模型效果。同时,开发者可以根据需求上传数据,在千帆ModelBuilder上对部分模型进行精调SFT,提升模型效果,打造您的个人专属模型。 千帆ModelBuilder作为 -

国产130亿参数大模型开源 性能超Llama2-13B
近日,由元象XVERSE研发的国产大模型XVERSE-13B正式开源,可免费商用。据了解,XVERSE-13B支持40多种语言、8192上下文长度。在多项中英文测评中,性能超过了同尺寸(130亿参数)的LIama2、Baichuan等。 GitHub链接:https://github.com/xverse-ai/XVERSE-13B XVERSE-13B大模型主要有这几个方面的特点: 模型架构方面,它是基于标准Transformer架构(Decoder-only),支持8K上下文长度,据称这也是目前同尺寸标准模型中
-
阿里云PAI使用LLaMA Factory微调LlaMA 3模型的教程
LLaMA Factory是什么?LLaMA Factory是一个开源微调框架,旨在简化和优化大规模语言模型的训练和部署。LLaMA Factory集成了业界广泛使用的微调技术,支持通过Web UI界面零代码微调大模型。本文将基于LlaMA 3模型,为大家介绍阿里云PAI使用LLaMA Factory微调LlaMA 3模型的具体操作方法。 点击进入:阿里云官网 前提条件: 1、创建工作空间。 2、创建DSW实例,其中关键参数配置如下: 实例规格选择:建议使用24 GB显存的A10(ecs.gn7i-c8g1.2xl -

UCloud GPU云主机 AI大模型最佳实践汇总
目前,AI大模型已经成为了人工智能的主流趋势。这些AI大模型需要庞大的计算资源和存储空间,因此部署AI大模型通常需要使用云计算服务。在众多云服务产品之中,GPU云主机是部署AI大模型的最佳选择之一。本文,小编就以UCloud为例,为大家整理了GPU云主机AI大模型最佳实践汇总。 UCloud GPU云主机购买方案介绍:《UCloud GPU云主机价格及配置信息》 一、ChatGLM-6B模型快速部署 ChatGLM-6B是清华大学知识工程和数据挖掘小组发布的一个开源的对话机器人。根据官方介绍,这是一个千亿参数规模的 -
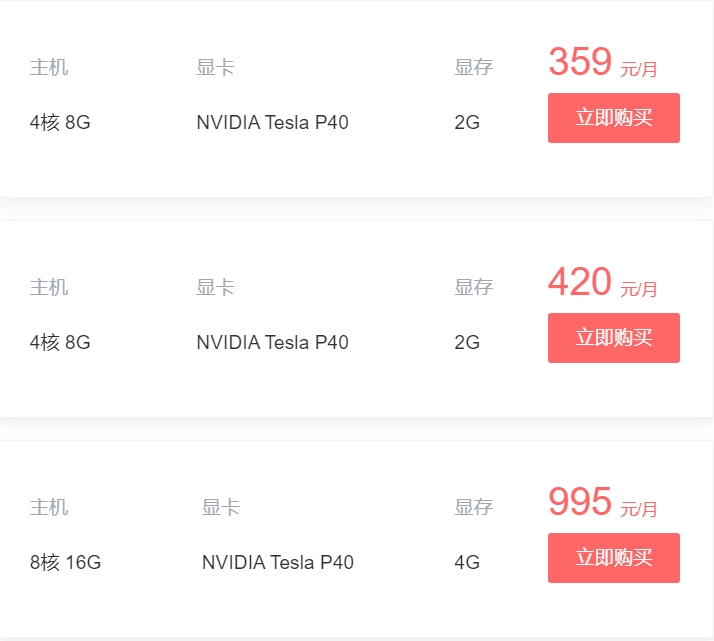
亿速云GPU云服务器怎么样?
亿速云是提供GPU算力的弹性计算服务,具有超强的并行计算能力,多用于深度学习、科学计算、视频处理、图形工作站、工程仿真等场景。亿速云GPU云服务器随时提供触手可得的算力。亿速云GPU云服务器具体方案介绍如下: 官网地址:www.yisu.com 亿速云GPU云服务器方案: 适用场景: 高性能的图形渲染和图形处理能力,适用于游戏开发和渲染等场景。 高效的视频编码和解码能力,适用于视频处理和流媒体服务等场景。 支持TensorFlow、PyTorch、Keras等主流深度学习框架。 支持LLaMA2、GPT-3、GPT -

国内各大模型盘点汇总
火爆全球ChatGPT让大模型技术进入更多人视野,国内大厂也都纷纷使出了自己的看家本领。百度发布文心大模型,华为发布盘古大模型,商汤发布日日新大模型,阿里发布通义千问大模型,腾讯即将发布混元AI大模型,科大讯飞“星火认知大模型”将在5月6日正式发布……一时间,各大企业AI大模型落地的消息接踵而至,今天就跟随小编一起来了解一下吧! 一、百度:文心大模型 百度文心大模型源于产业、服务于产业,是产业级知识增强大模型。百度通过大模型与国产深度学习框架融合发展,打造了自主创新的AI底座,大幅降低了AI开发和应用的门槛,满足真
-

书生·浦语怎么样? 书生·浦语开源吗
说到2023年的大模型战场,那只能用神仙打架来形容。单从国内市场来看,据不完全统计,已经诞生了80多个大模型,并且数量还在不断上涨。在国产大模型当中,大家比较熟悉的有文心一言、通义千问、讯飞星火等。接下来给大家介绍的是另一个国产大模型——书生·浦语。 书生·浦语怎么样?书生·浦语由商汤科技、上海AI实验室联合香港中文大学、复旦大学及上海交通大学发布。书生·浦语具有1040亿参数,是在包含1.6万亿token的多语种高质量数据集上训练而成。 书生・浦语联合团队选取了 20 余项评测对其进行检验,其中包含全球最具影响力