







































-
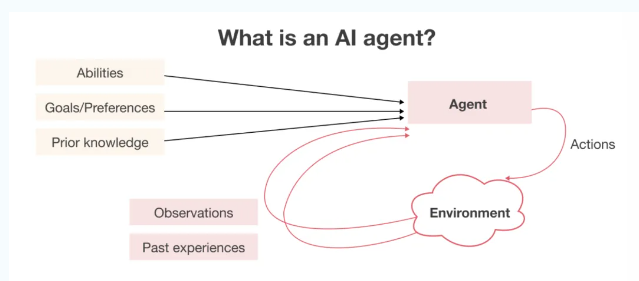
什么是AI Agent AI Agent能干啥
AI Agent即人工智能代理,也就是大家常说的智能体。AI Agent是以大语言模型为大脑驱动的系统,具备自主理解、感知、规划、记忆和使用工具的能力,能够自动化执行完成复杂任务的系统。AI Agent能够在各个领域中的广泛应用,包括医疗健康、金融服务、智能制造、自动驾驶以及客户服务等。下文就详细地带大家一起来看看吧。 一、什么是AI Agent AI Agent是一种能够感知环境、做出决策并采取…- 57
- 0
-
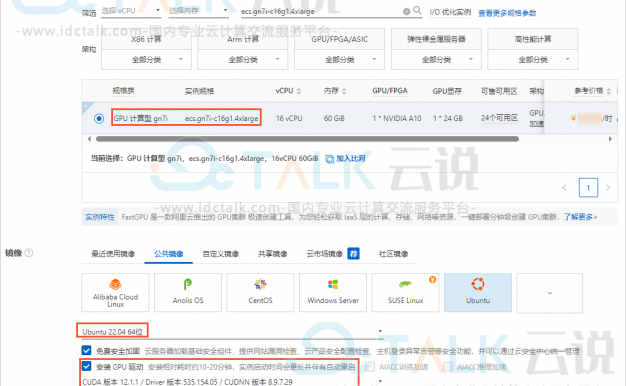
如何在阿里云GPU云服务器上快速搭建个人版“对话大模型”
Alpaca大模型是一款基于LLaMA的大语言模型,它可以模拟自然语言进行对话交互,并协助用户完成写作、翻译、编写代码、生成脚本等一系列创作任务。本文基于Alpaca大模型,为大家介绍如何在阿里云GPU云服务器上快速搭建个人版“对话大模型”,仅供参考。 一、创建并配置阿里云GPU云服务器 阿里云GPU云服务器是提供GPU算力的弹性计算服务,具有超强的计算能力,服务于深度学习、科学计算、图形可视化、…- 48
- 0
-
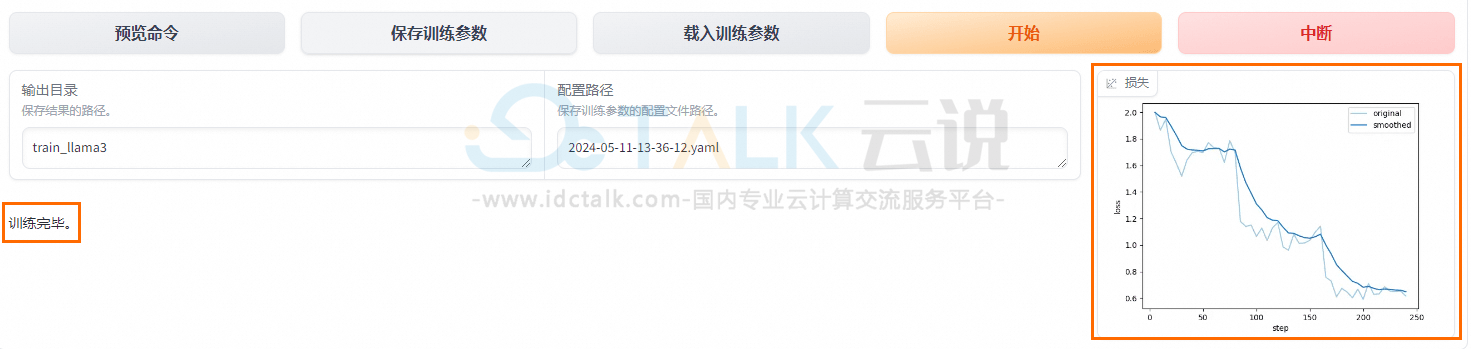
阿里云PAI使用LLaMA Factory微调LlaMA 3模型的教程
LLaMA Factory是什么?LLaMA Factory是一个开源微调框架,旨在简化和优化大规模语言模型的训练和部署。LLaMA Factory集成了业界广泛使用的微调技术,支持通过Web UI界面零代码微调大模型。本文将基于LlaMA 3模型,为大家介绍阿里云PAI使用LLaMA Factory微调LlaMA 3模型的具体操作方法。 点击进入:阿里云官网 前提条件: 1、创建工作空间。 2、…- 117
- 0
-

微软开源AutoGen框架 简化大语言模型工作流程
AutoGen是一款由微软发布的AI框架,可以简化大语言模型工作流的编排、优化和自动化。AutoGen支持用户创建自主、可扩展、多才多艺的人工智能代理团队,协作高效,操作自如,可独立执行广泛的复杂任务。 AutoGen的主要特点: 独立创建:AutoGen支持用户根据自身需求构建智能代理团队,灵活应对各种任务。 多才多艺:AutoGen的代理团队拥有多领域的技能,能够胜任各类任务,无论是娱乐、办公…- 40
- 0
-
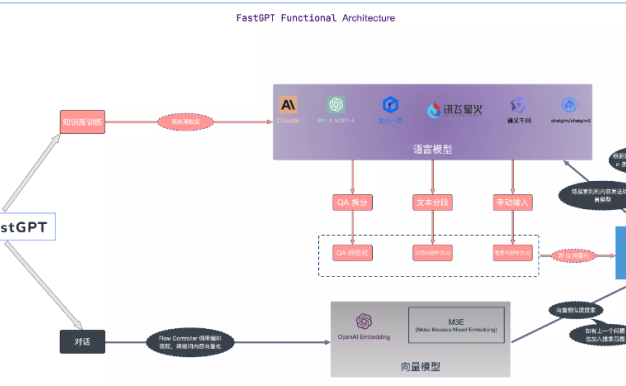
FastGPT是什么?FastGPT能干嘛?
FastGPT是什么?FastGPT是一个基于大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。FastGPT通过Flow可视化进行工作流编排可以实现复杂的问答场景! FastGPT允许用户构建本地知识库,以提高AI的理解能力和应用场景的适应性。该系统的设计旨在让AI更好地理解用户需求并提供更准确的回答。那么FastGPT能干嘛?下文小编就为大家总结一下FastGPT的功能,如下…- 53
- 0
-
阿里云通义千问14B模型开源
9月25日,阿里云发布通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,免费开源可使用。 魔搭社区模型地址:https://www.modelscope.cn/models/qwen/Qwen-14B/summary Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推理、认知…- 110
- 0
-
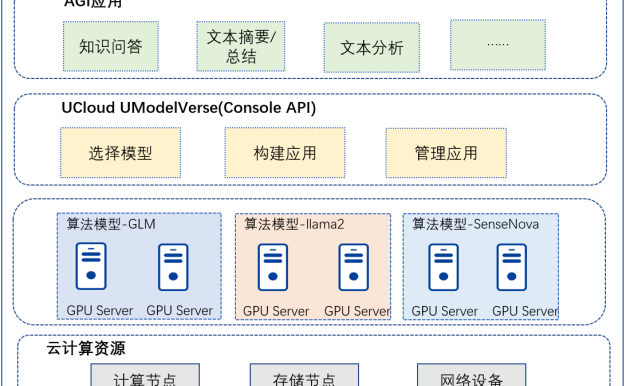
UCloud发布模型服务平台UModelVerse
近日,知名云计算服务商UCloud推出了全新的MaaS服务产品——模型服务平台UModelVerse。据悉,UModelVerse平台旨在为客户快速搭建AGI应用的能力,将集成多家算法公司以及部分热门开源模型,借助于卓越的中文语料推理能力,让用户能够以自然语言进行查询并获得准确的答案。 UModelVerse平台的应用场景包括但不限于以下几类: 一、文本创作 在文本创作方面,UModelVerse…- 42
- 0
-
开源类ChatGPT模型Falcon 180B发布
近日,阿联酋阿布扎比技术创新研究所(TII)在官网发布了,目前性能最强的开源大语言模型之一Falcon 180B。 TII表示,Falcon 180B拥有1800亿参数,使用4096个GPU在3.5万亿token 数据集上进行训练,这也是目前开源模型里规模最大的预训练数据集之一。Falcon 180B有基础和聊天两个模型,允许商业化。 今年5月,TII曾经发布过另一款类ChatGPT开源大语言模型…- 95
- 0
-
百川智能发布第二代开源模型Baichuan 2
9月6日,百川智能发布第二代开源模型Baichuan 2,正式开源微调后的Baichuan 2-7B、Baichuan 2-13B、Baichuan 2-13B-Chat与其4bit量化版本。以上模型均免费可商用,已在阿里云AI模型社区魔搭ModelScope首发上架。 百川智能此次还开源了模型训练的Check Point,并宣布将发布Baichuan 2技术报告,详细介绍Baichuan 2的训…- 89
- 0
-

腾讯正式发布混元大模型 参数规模超千亿
9月7日,在2023腾讯全球数字生态大会上,腾讯混元大模型正式对外亮相,同时宣布通过腾讯云对外开放,用户可以直接调用API接口,或者将混元作为基底模型,在公有云上进行精调。同时,在微信小程序搜索“腾讯混元助手”,即可申请内测体验。 根据发布信息显示,腾讯混元大模型拥有超千亿参数规模,预训练语料超2万亿tokens,具有强大的中文理解与创作能力、逻辑推理能力,以及可靠的任务执行能力。 腾讯集团高级执…- 42
- 0
-

AI+软件研发数字峰会·深圳站
会议时间:2023年11月24日-25日 会议地点:深圳 主办单位:AiDD大会组委会 承办单位:中智凯灵(KeyLink) 协办单位:深圳市软件行业协会 大会背景 伴随着人工智能(AI,特别是大语言模型)在众多行业领域的广泛应用及其带来的颠覆性变革,软件的开发模式、方式和实践都可能会发生巨大的变化。为助力更多企业在人工智能的浪潮中乘风破浪,“AI+软件研发数字峰会(AiDD)”应运而生,旨在帮助…- 47
- 0
-

国内11家大模型获批上线 向全社会开放使用
8月31日,11家首批通过《生成式人工智能服务管理暂行办法》备案的大模型获批上线,将通过Web、APP、API等方式,为全社会提供多种生成式AI服务。其中北京5家、上海3家、广东2家、安徽1家。 北京5家分别是百度的文心一言、抖音的云雀、百川智能的百川大模型、清华系AI公司智谱华章旗下的智谱清言以及中科院的紫东太初。上海3家是商汤的商量SenseChat、MiniMax的ABAB大模型、上海人工智…- 65
- 0
-

百度文心一言向全社会开放
8月31日,文心一言率先向全社会全面开放,广大用户可以在应用商店下载“文心一言APP”或登陆“文心一言官网”体验。据悉,百度后期还将开放一批经过全新重构的AI原生应用,让广大用户充分体验生成式AI的理解、生成、逻辑、记忆四大核心能力。 文心一言官网地址:https://yiyan.baidu.com 文心一言是百度推出的全新一代知识增强大语言模型,能够与人对话互动,回答问题,协助创作,高效便捷地帮…- 26
- 0
-
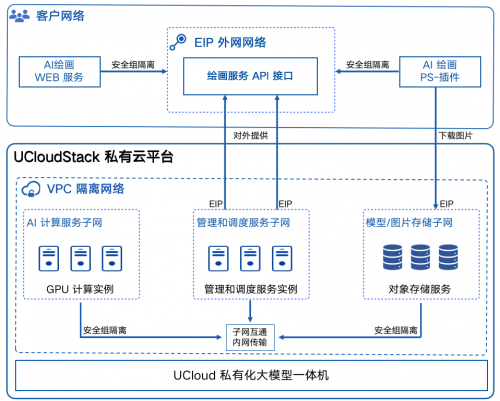
UCloud推出国内第一款私有化大模型一体机
Al生成与大模型,作为当今人工智能领域炙手可热的话题,为相关产业链带来新的机遇和挑战。在2023世界人工智能大会上,UCloud(优刻得)分享了“中立安全云计算助力大模型发展”的技术产品、工程能力和生态建设等诸多能力,特别提到私有化是垂直大模型未来的发展方向。 面向政府、金融、教育、制造、基金等行业客户及大模型企业的大模型私有化交付场景,UCloud推出国内第一款私有化大模型一体机,内置优刻得自主…- 277
- 0
-

中国工程院院士刘韵洁:国内发展大模型的机会 在通用行业大模型
8月20日,中国工程院院士、紫金山实验室主任刘韵洁接受采访时判断,中国发展大模型的机会在于通用行业大模型。 在日前举办的2023中国算力大会间隙,刘韵洁接受媒体采访时说,“大模型方面,美国走在前面。”中国需要在算力、数据、网络等方面,进行深入的、专家层面的研究,制定出应对措施和办法。 他坦言:“当前大模型‘火’,大家都去做大模型,或GPU价格涨得厉害,大家都去搞GPU,不是说这些东西不能搞,而是国…- 21
- 0
-

快手推出自研大语言模型“快意” 多项性能接近ChatGPT
8月21日,快手AI团队宣布推出,从0到1独立自主研发的系列大语言模型“快意”(KwaiYii)。据悉,“快意”包含KwaiYii-13B-Base预训练模型和KwaiYii-13B-Chat对话模型。 其中,Base预训练模型在MMLU、CMMLU、C-Eval等权威的中/英文测试平台中,在同等模型中处于领先水平。Chat对话模型具备内容创作、信息咨询、数学推理、生成代码等能力,人工评估结果表明…- 88
- 0
-

文心一言大模型上线5个原生插件
8月16日,百度首席技术官王海峰在WAVE SUMMIT深度学习开发者大会上表示,文心一言大模型现已上线 5 个原生插件:百度搜索、览卷文档、E言易图、说图解画、一镜流影。同时,文心一言现已支持一次同时使用3个插件,官方称在扩展大模型能力边界的同时,更能适应场景需要。 百度搜索无需多说,作为国内最大的搜索引擎,其强大的搜索能力毋庸置疑。 览卷文档,原名ChatFile,能够基于文档完成摘要、问答、…- 90
- 0
-

书生·浦语怎么样? 书生·浦语开源吗
说到2023年的大模型战场,那只能用神仙打架来形容。单从国内市场来看,据不完全统计,已经诞生了80多个大模型,并且数量还在不断上涨。在国产大模型当中,大家比较熟悉的有文心一言、通义千问、讯飞星火等。接下来给大家介绍的是另一个国产大模型——书生·浦语。 书生·浦语怎么样?书生·浦语由商汤科技、上海AI实验室联合香港中文大学、复旦大学及上海交通大学发布。书生·浦语具有1040亿参数,是在包含1.6万亿…- 71
- 0
-

腾讯云TI平台正式上架 全面接入Llama 2等主流开源模型
8月16日,在2023中国数字经济创新发展大会上,腾讯高级执行副总裁、云与智慧产业事业群CEO汤道生宣布腾讯云TI平台正式上架。 据悉,腾讯云TI平台已经全面接入Llama 2、Falcon、Dolly、Vicuna、Bloom、Alpaca等20多个主流模型!这些主流模型支持直接部署调用、应用流程简单、可全程低代码操作。企业、开发者可以根据不同细分场景的业务需求,灵活选择各类大模型,降低大模型使…- 74
- 0
-
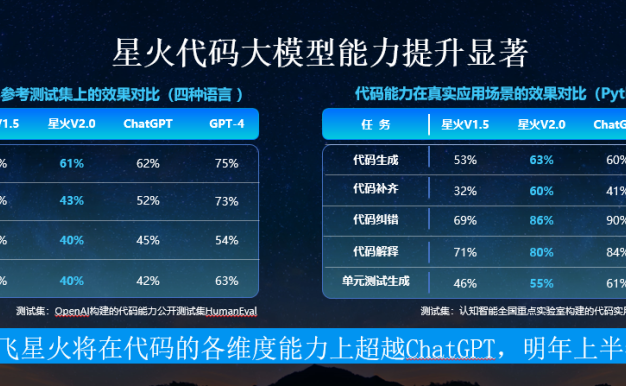
讯飞星火认知大模型V2.0重磅发布 推出代码能力与多模态能力
8月15日,讯飞星火认知大模型V2.0重磅发布!在文本生成、语音理解、知识问答、逻辑推理、数学能力等通用能力持续提升的同时,讯飞星火V2.0重磅推出了代码能力与多模态能力。 讯飞星火V2.0已具备“代码生成、代码补齐、代码纠错、代码解释、单元测试生成”等能力,并且在业界参考测试集与真实应用场景均达到优异效果,逼近国外领军者。 讯飞星火V2.0升级发布的多模态能力,已实现图像描述、图像理解、图像推理…- 96
- 0
-

金蝶发布国内首个财务大模型
8月8日,金蝶“2023全球创见者大会”在深圳成功举办。会上,金蝶云·苍穹GPT大模型重磅发布,定位为最懂管理的企业级大模型平台。苍穹GPT率先推出国内首个财务大模型,并现场开放体验,为全球创见者们带来管理领域前所未有的人工智能化变革,引领企业数字化管理迈入大模型时代。 据了解,苍穹GPT作为金蝶云EBC(企业业务能力,EnterpriseBusinessCapability)的智能新引擎,是金蝶…- 37
- 0
-

IBM将提供类ChatGPT开源模型Llama 2 最高700亿参数
8月10日,IBM在官网宣布,将在watsonx.ai和数据平台中,提供700亿参数开源大语言模型Llama 2。Llama 2是科技、社交巨头Meta在上个月开源的一款类ChatGPT大语言模型并允许商业化。Llama 2是在Llama基础之上构建而成,拥有70亿、130亿和700亿三种参数,可用于开发各种生成式AI产品,是目前最强开源大语言模型之一。 免费试用地址:https://datapl…- 40
- 0
-
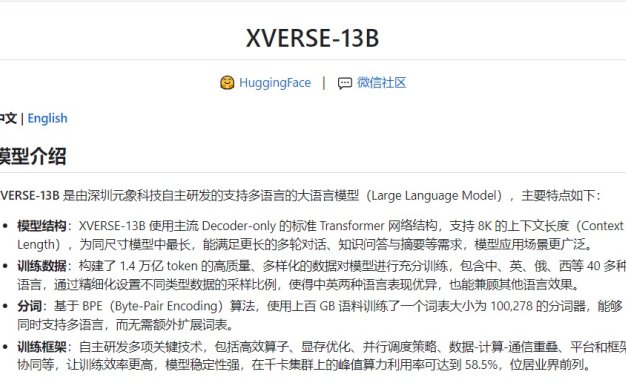
国产130亿参数大模型开源 性能超Llama2-13B
近日,由元象XVERSE研发的国产大模型XVERSE-13B正式开源,可免费商用。据了解,XVERSE-13B支持40多种语言、8192上下文长度。在多项中英文测评中,性能超过了同尺寸(130亿参数)的LIama2、Baichuan等。 GitHub链接:https://github.com/xverse-ai/XVERSE-13B XVERSE-13B大模型主要有这几个方面的特点: 模型架构方面…- 68
- 0
-

曹植大模型是什么? 曹植大模型在哪用
曹植大模型是什么?曹植大模型是达观数据研发的一款垂直领域大语言模型,也是国内首个垂直行业专用的自主可控的GPT大语言模型,具有长文本、垂直化和多语言的特点。 一、长文本 达观数据在长文本处理领域深耕多年,研发的“曹植”大模型特别擅长做长文档的写作、审核、润色、翻译等。“曹植”通过其卓越的自动化写作能力,可准确完成多类型、复杂结构的长文本写作,自动起草多种类型的文档,轻松应对长篇大论的要求。无论是白…- 99
- 0
























