







































-
OpenAI宣布所有用户无限用Sora
近日,OpenAI在第13天的直播中宣布将在假期期间为所有用户无限制的提供文生视频模型Sora,轻松跳过烦人的队列等待。 对于很多用户来说,在圣诞节能够获得这样的圣诞礼物,是一件非常不错的事。 应用Patch是Sora的核心技术之一,允许在大量的图像和视频数据上进行密集训练。从每一个存在的视频中剪出的Patch,可以被堆叠起来并输入到模型中。这种基于Patch而非视频全帧的训练方式,使得Sora能…...- 0
- 37
-
OpenAI正式发布Sora Turbo
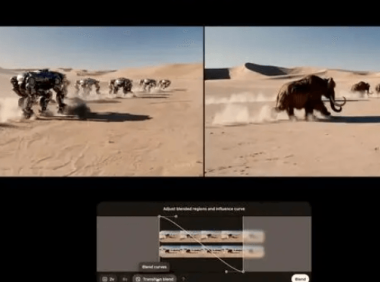
近日,OpenAI在第三天技术直播中正式发布了Sora Turbo。该模型是目前全球生成时长最高的视频模型之一,能通过文本直接生成最多20秒1080P视频,同时支持文本+图片/视频,生成特定视频内容,使得模型的生成效果更加可控。 目前,Sora已经正式进入使用阶段,ChatGPT Plus和Pro会员无需额外费用就能使用。 为了让用户能够更好地使用Sora,OpenAI还开发了全新UI,同时提供社…...- 0
- 40
-

腾讯开源了最强的类Sora文生视频模型HunyuanVideo
最近,腾讯开源了目前最强的类Sora混元视频生成大模型(HunYuan-Video)。模型参数量130亿,具备物理模拟、一镜到底、文本语义还原度高、动作一致性强、色彩分明、对比度高等技术特性。 腾讯混元视频生成模型HunYuan-Video是一款突破性的视频生成模型,提供超写实画质质感,能够在真实与虚拟之间自由切换。它打破了小幅度动态图的限制,实现完整大幅度动作的流畅演绎。 HunYuan-Vid…...- 0
- 59
-
Open-Sora开源大升级 支持16s视频生成和720p分辨率
开源文生视频模型Open-Sora目前已经进行了大升级,现已支持16s视频生成和720p分辨率。并且可以处理任何宽高比的文本到图像、文本到视频、图像到视频、视频到视频和无限长视频的生成需求。 Open-Sora坚持全部开源,包含Open-Sora的模型架构、最新的模型权重、多时间/分辨率/长宽比/帧率的训练流程、数据收集和预处理的完整流程、所有的训练细节。 据最新结果显示,Open-Sora在gi…...- 0
- 41
-


LTX Studio:生成式AI电影制作平台,比Sora更专业更精准
2月29日,著名AI平台Lightricks宣布,推出生成式AI电影制作平台—LTX Studio。 用户可以通过输入文本来生成超过25秒的微电影视频,并且可以对视频的镜头切换、角色、场景一致性、摄像机、灯光等进行可视化精准控制。这些视频由神经网络完成,用户无法对生成的内容进行任何内容控制。目前LTX Studio支持免费申请试用,将在3月27日开启第—批测试。 美国人工智能公司OpenAI于2月…...- 0
- 245
-


OpenAI重磅推出首个文生视频模型Sora
2月16日凌晨,OpenAI发布了首个文生视频模型Sora。Sora基于DALL-E与GPT框架,通用人工智能(AGI)迎来里程碑。 Sora取自日语中的“天空”一词,根据官方介绍,该模型可以生成长达一分钟的视频,同时保持视觉品质并遵循用户提示。它能够生成具有多个角色、特定类型的运动以及精确的主题和背景细节的复杂场景。除了能够仅由文本指令生成视频外,该模型还能够获取现有的静态图像并从中生成视频,并…...- 0
- 22
-

OpenAI推出最新文生图模型
近日,OpenAI对GPT-4o和Sora进行了重大更新,推出了全新的文生图模型。该模型不仅能够生成图像,还支持自定义操作、连续发问、风格转换以及制作图像PPT等多种实用功能。 它生成的图像非常逼真,肉眼几乎看不出任何破绽,在精细度、细节和文本遵循方面非常出色,可以媲美甚至在某些功能超过该领域的头部平台Midjourney。 OpenAI联合创始人兼首席执行官表示,新的文生图模型是一项令人难以置信…...- 0
- 11
-

OpenAI宣布将进行12天的技术分享活动
美国AI初创公司OpenAI于近日宣布将进行为期12天的技术分享活动,每个工作日都会有一个直播,展示最新技术或产品演示,包括许多重磅内容和一些小惊喜。 这次12天的技术分享活动是史无前例的,在整个科技界都非常罕见。据网友预测,本次活动内容可能包括:发布文生视频模型Sora、为ChatGPT引入圣诞老人风格语音、增强ChatGPT的高级语音模式并增加视觉功能、发布o1-preview、展示即将推出的…...- 0
- 23
-


Stable Diffusion 3即将在6月12日开源
6月3日,Stability AI的联合首席执行官在AMD的产品发布会宣布,文生图模型Stable Diffusion 3即将在6月12日正式开源。 此次开源的Stable Diffusion 3的Medium模型有20亿参数,在照片真实感、样式、图片质量、算力资源消耗等方面都进行了大幅度优化,将比前两代更好。同时Stable Diffusion 3也是对标闭源文生图产品Midjourney、DA…...- 0
- 60
-


谷歌发布Project Astra 全面叫板OpenAI
近日,在谷歌I/O开发者大会上的主题演讲中,谷歌展示了由升级后Gemini模型驱动的AI助手项目Project Astra、对标Sora的文生视频模型Veo,以及在硬件方面发布的第六代Tensor处理器单元(TPU)Trillium芯片。 其中,Project Astra是谷歌DeepMind发布的一款全新的AI代理产品,可以实现跨文本、音频、视频多模态实时推理,丝毫不逊色OpenAI发布的GPT…...- 0
- 59
-


OpenAI推出新工具 能识别由DALL-E 3生成的内容
最近,OpenAI在官方社交媒体账号称,推出新的分类器,以帮助研究人员们识别由DALL·E 3所生成的内容。另推出一个媒体管理器,主要是面向媒体行业、内容创作者的产品,帮助控制自己的知识产权内容是否会被OpenAI搜集用于训练AI模型。 目前,OpenAI已经开放了DALL·E 3识别器的API,开发人员从今天开始至7月31日可申请试用。OpenAI会在8月31日之前公布获取使用权限的名单。 识…...- 0
- 48
-
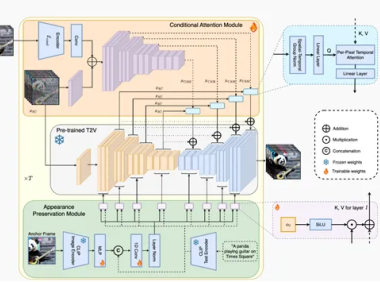
StreamingT2V即将开源 两分钟生成1200帧的长视频
最近,Picsart AI Resarch等机构联合推出了StreamingT2V视频模型。StreamingT2V不仅能够根据文本描述生成长视频,而且能够保持视频的时间连贯性和高质量图像帧,其生成的视频长度可达到1200帧,即两分钟的播放时长。 长视频生成模型StreamingT2V的出现,标志着文本到视频内容生成领域迈入了一个新的里程碑。StreamingT2V在高速运动方面非常优秀,这为开发…...- 0
- 90























